发布时间:2021-04-19 16: 36: 58
一般情况下,图像型PDF文档就如同图像一样,是无法进行复制、搜索等操作的。但特殊情况下,我们可以通过文本识别的方式,将文档中的图像、文本等智能识别出来,就能实现复制图像型PDF文档内容的功能。
那么,怎么才能对PDF文档进行智能识别呢?我们可以使用专业的文本识别软件ABBYY FineReader PDF 15来实现这一功能。接下来,一起来看看怎么应用文本识别的功能。

一、背景识别
我们在ABBYY FineReader PDF 15中打开目标文档后,如图2所示,软件会自动开启背景识别的功能。背景识别,实际上就是对文档进行智能文本识别的过程。
图像型PDF文档在经过背景识别后,会转换为可搜索的PDF文档形式,我们可以对背景识别后的内容执行复制操作。
背景识别完成后,如图3所示,ABBYY FineReader PDF 15底部会出现“背景识别完成”的标识。
二、进入编辑模式
完成文本识别后,如图4所示,我们就可以单击ABBYY FineReader PDF 15的编辑按钮,开启文档文本、图片的编辑。
那么,我们可以复制文档中的哪些内容呢?
1、复制图片
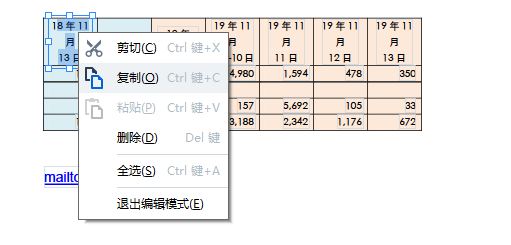
在编辑模式下,如图5所示,右击图片后,即可使用右键快捷菜单中的“复制”选项复制文档图片。

2、复制文本
当文档完成背景识别后,如图6所示,文本段落的四周会出现一个文本框,表明该文本段落处于可编辑状态。
此时,我们就可以选中文本框中的文本,并使用其右键快捷菜单中的“复制”选项,复制所选的文本。
3、复制表格中的文本
除了可以复制文本段落外,对于表格中的文本,我们同样可以通过选中的方式复制单元格中的文本。
如需复制整个表格的话,则需要使用到ABBYY FineReader PDF 15的OCR编辑器功能,进行表格区域的识别。
三、小结
通过使用ABBYY FineReader PDF 15的智能识别功能,我们可以将图像型PDF文档识别为可搜索的PDF文档,进行文本、图像的复制。
另外,借助更高级的OCR编辑器,更可实现表格的复制,如需了解该项功能,可前往ABBYY FineReader PDF 15中文网站。
作者:泽洋
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

PDF文字怎么提取出来 PDF文字怎么复制到Word
PDF文件能够让接收者查看原本的文字格式,但这也让接收者有困扰,想要在PDF文件中检索出重要信息,往往需要从头翻阅,想要将PDF中的文字提取出来,需要逐字敲打。因此很多人想知道PDF文字怎么提取出来,PDF文字怎么复制到Word中,下面就给大家介绍一下如何解决这两个问题。...
阅读全文 >
Word转PDF怎么不分页 Word转PDF怎么保留导航
有许多平台上传文件时都不能直接上传文档格式,而是要求上传PDF格式,然而PDF格式的文件又不能直接进行编辑,因此我们需要将Word文档格式转换成PDF格式之后才能提交。但这也引发了一系列的问题,例如转换成Word文档后存在空白页、转换后格式发生变化等情况,今天我们就来说一说Word转PDF怎么不分页,Word转PDF怎么保留导航。...
阅读全文 >
PDF转成图片的方法 PDF转图片不清晰怎么办
PDF文档和图片都是常用的文件格式,在工作中我们需要根据不同的需求来灵活地对文件的格式进行更改,这就需要我们掌握PDF转成图片的方法。PDF转图片不清晰怎么办?下文中会为大家进行详细地解答。...
阅读全文 >

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >


