发布时间:2021-06-25 15: 54: 57
当我们使用ABBYY FineReader PDF 15(Win系统)的PDF编辑器打开PDF文档时,ABBYY的背景识别功能将自动开启。我们可以直接搜索和复制没有文本图层的文本和图片,例如扫描的文档和从图像文件创建的文档。
背景识别功能会把临时文本图层添加到文档,让我们可以标记、复制和搜索文档中的文本内容,我们还可以替换PDF文档中现有的文本图层,或者把永久文本图层添加到PDF文档中,让使其他阅读者也可以使用这些功能。
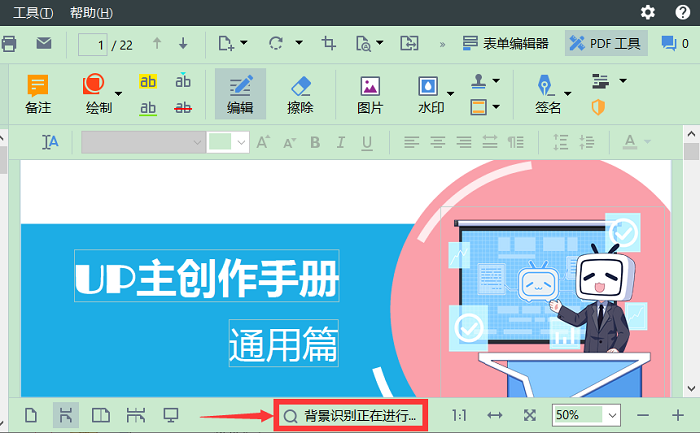
图1:ABBYY自动进行的背景识别
在顶部工具栏上直接使用识别文档功能。或者在菜单“文件>识别文档>识别文档...”中使用这项功能。
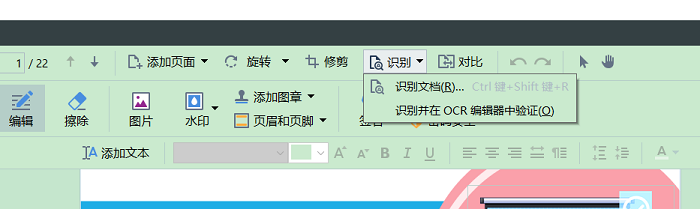
图2:识别文档
在打开的对话框中,指定适当的OCR语言。
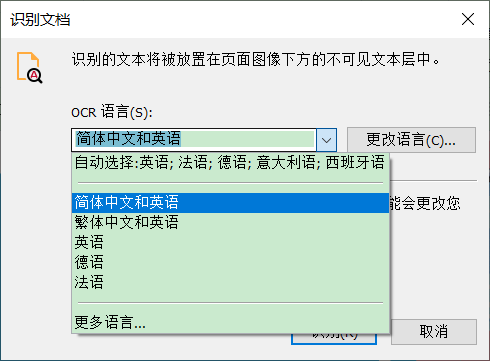
图3:OCR识别语言
默认为“简体中文和英语”,我们可以根据文档内容选择具体语言,还可以在“更多语言”中选择其他语言。
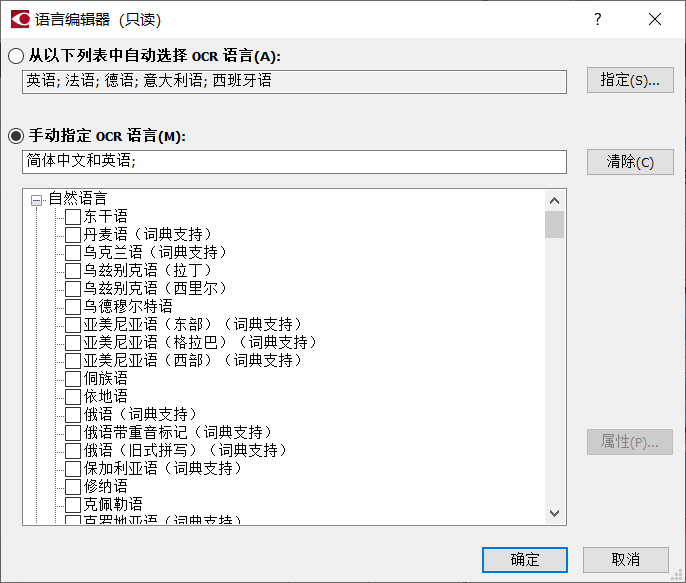
图4:自定义选择其他语言
如果想要提高OCR识别的质量,我们可以启用图像预处理设置,不过使用图像处理可能会导致文档部分内容的排版出现改动。
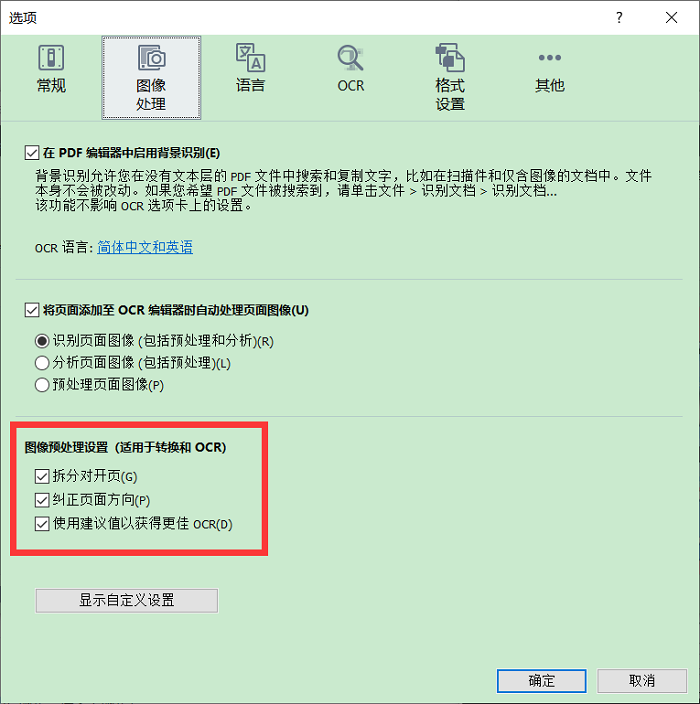
拆分对开页:ABBYY会自动将包含对开页的图像拆分为两个彼此只包含一个页面的图像。
纠正页面方向:ABBYY会检测文本方向并在必要时更正。
使用建议值以获得更佳OCR:ABBYY应用需要的预处理设置。
点开“显示自定义设置”按钮后会出现更多可勾选选项。
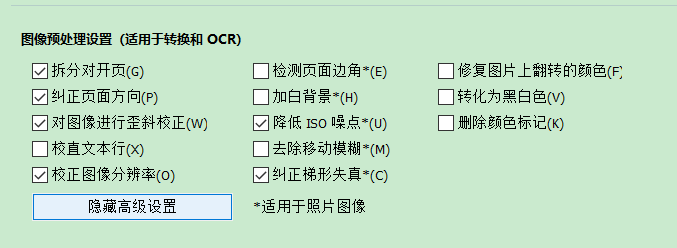
图5:更多自定义设置选项
在确定预设设置后,我们输出的文件就会包含可搜索的文本图层。
将页面从一个文件添加到一个 PDF 文档时,或扫描纸质文档时,我们也可以添加文本图层,点击“添加页面 > 图像处理设置”进行设置,指定文档的语言。
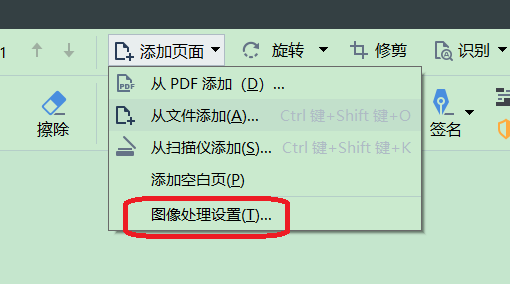
图6:图像处理设置
如果我们想要检查已识别的文本,可以进行识别并在OCR编辑器中验证。以上便是ABBYY FineReader PDF 15里的OCR功能在PDF文件中的使用方法。大家如果想要了解更多关于ABBYY的OCR识别技巧,尽情关注ABBYY中文网哟。
作者:∅
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

ABBYY怎么识别图片上的文字 ABBYY怎么拆分Word分段
ABBYY Finereader 是一款专业的OCR文字识别软件,可以快速准确的扫描各种文档上的文字,但对于初次接触这款软件的小伙伴来说,可能还不太了解ABBYY的具体用法。别担心,今天将为大家介绍ABBYY怎么识别图片上的文字,ABBYY怎么拆分Word分段的操作步骤。...
阅读全文 >

abbyy finereader需要付费吗 abbyy软件有免费的吗
ABBYY是一家全球领先的技术公司,专注于开发和提供智能文档处理和数据捕获解决方案。ABBYY的主要产品包括ABBYY FineReader,这是一款流行的OCR软件,可将扫描的文档和图像转换为可编辑的文本格式。...
阅读全文 >

为什么word转PDF图片模糊 word转pdf怎么保持图片清晰度
将Word文档转换为PDF格式可以提高文档的安全性、兼容性和可读性,同时方便打印、分享和浏览。但是在将Word文档转换为PDF格式之后,有时原先的图片会变得模糊,这是为什么呢?下面一起来了解为什么word转PDF图片模糊,word转pdf怎么保持图片清晰度的相关内容。...
阅读全文 >
电脑扫描文件在哪里找 电脑扫描文件怎么扫描成pdf
将文件扫描成电子版是我们日常生活中保存重要文件的方式之一,用电脑扫描文件进行存档,以后想要再使用可以快速找到,节约时间,提高效率,而且转换成PDF便于传输,浏览方便。今天小编给大家讲讲电脑扫描文件在哪里找,电脑扫描文件怎么扫描成PDF。...
阅读全文 >


