发布时间:2021-05-19 09: 44: 25
ABBYY FineReader PDF 15配备了智能的OCR文本识别功能,不仅能识别PDF文档,而且还能识别纯图像文件,很适合用于纸质文件的数字化处理。
本文将会针对ABBYY FineReader PDF 15的图像文本识别功能,介绍一些图像识别的小技巧,提高软件的文本识别效率。
一、图像文件的预处理
图像文件的预处理,是ABBYY FineReader PDF 15提供的一项相当实用的功能,该功能可帮助我们预先处理一些拍摄失误,如页面方向错误、图像倾斜等。
如图1所示,单击“在OCR编辑器中打开”功能,该功能可用于图像的文本识别。
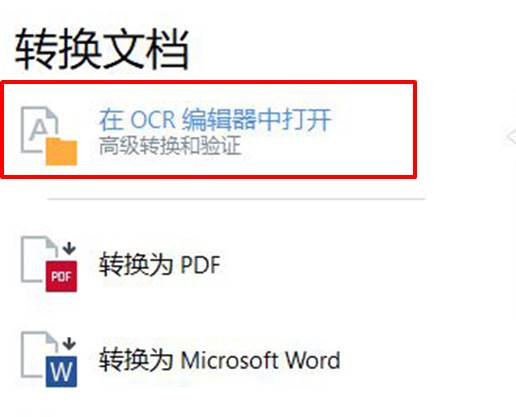
接着,如图2所示,在打开文件窗口的右下角出现的“添加页面时自动处理页面图像”的功能,勾选该选项即可在打开图像后,自动执行图像预处理操作。
那么,该功能包含了哪些预处理选项呢?我们可以单击“选项”按钮进一步了解。
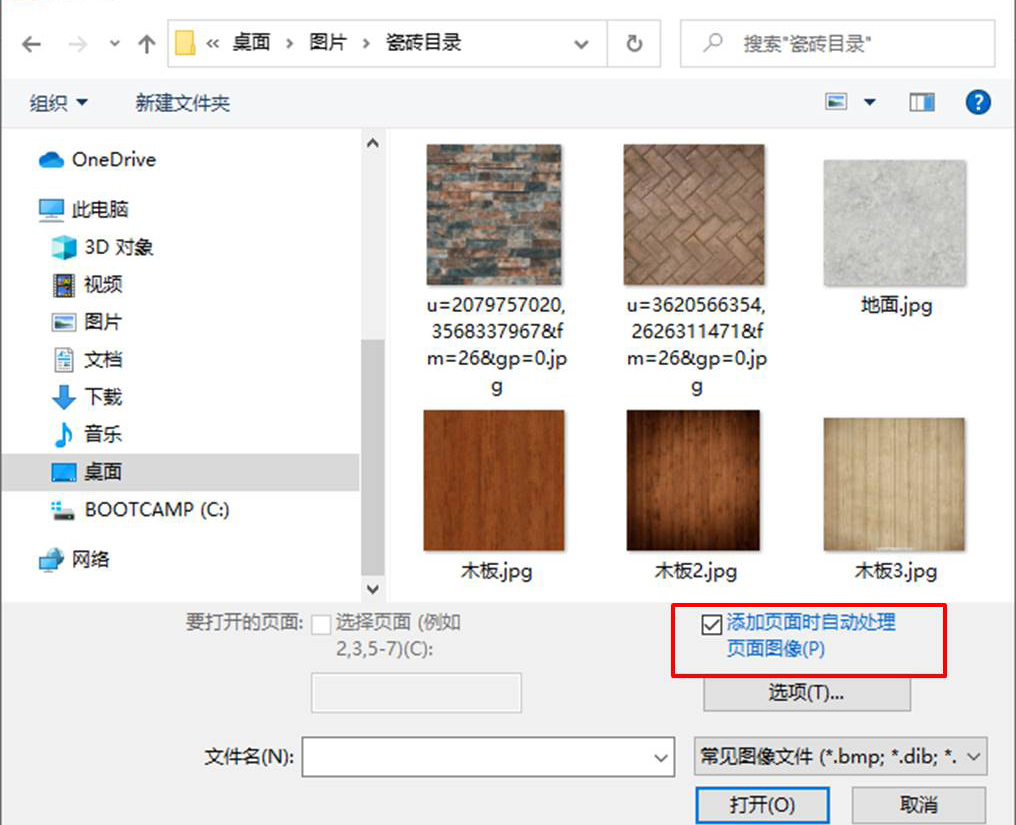
如图3所示,在“图像预处理设置”中,可以看到,ABBYY FineReader PDF 15默认开启了“拆分对开页”、“纠正页面方向”、“对图像进行歪斜校正”等图像处理功能。

以图4所示的图像为例,该图像包含了两个页面,并且存在页面方向错误。

完成了图像预处理后,如图5所示,可以看到,图像已经被拆分为两页,并完成了页面方向的纠正。

二、手动设置区域功能
在图像识别的过程中,我们也有一些小技巧可以使用。
当我们将图像导入到OCR编辑器时,ABBYY FineReader PDF 15会自动进行图像区域的识别。
在一些特殊的情况下,如识别证件图像时,我们可能需要准确地保留原文的格式,在这种情况下,我们可以运用手动区域设置的功能,将识别为文本的区域,修改为图片区域,保留其原来的格式。
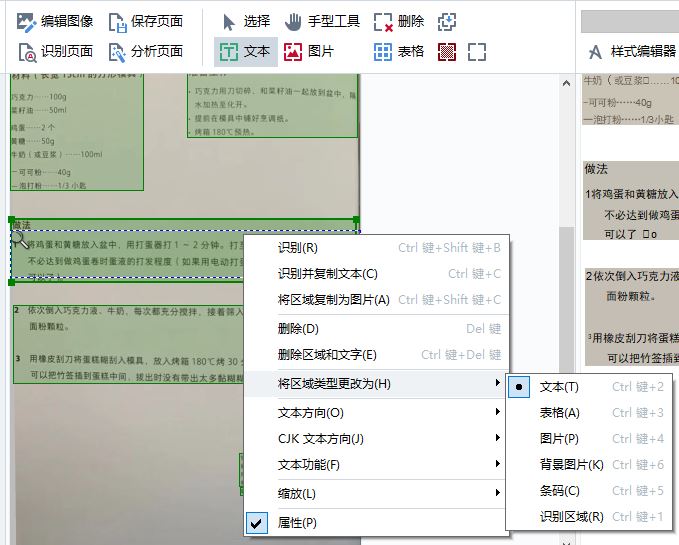
除了手动设置区域功能外,ABBYY FineReader PDF 15还提供了区域属性的功能,以帮助我们识别一些特殊的文本格式,如反转的文本、旋转过的文本等。
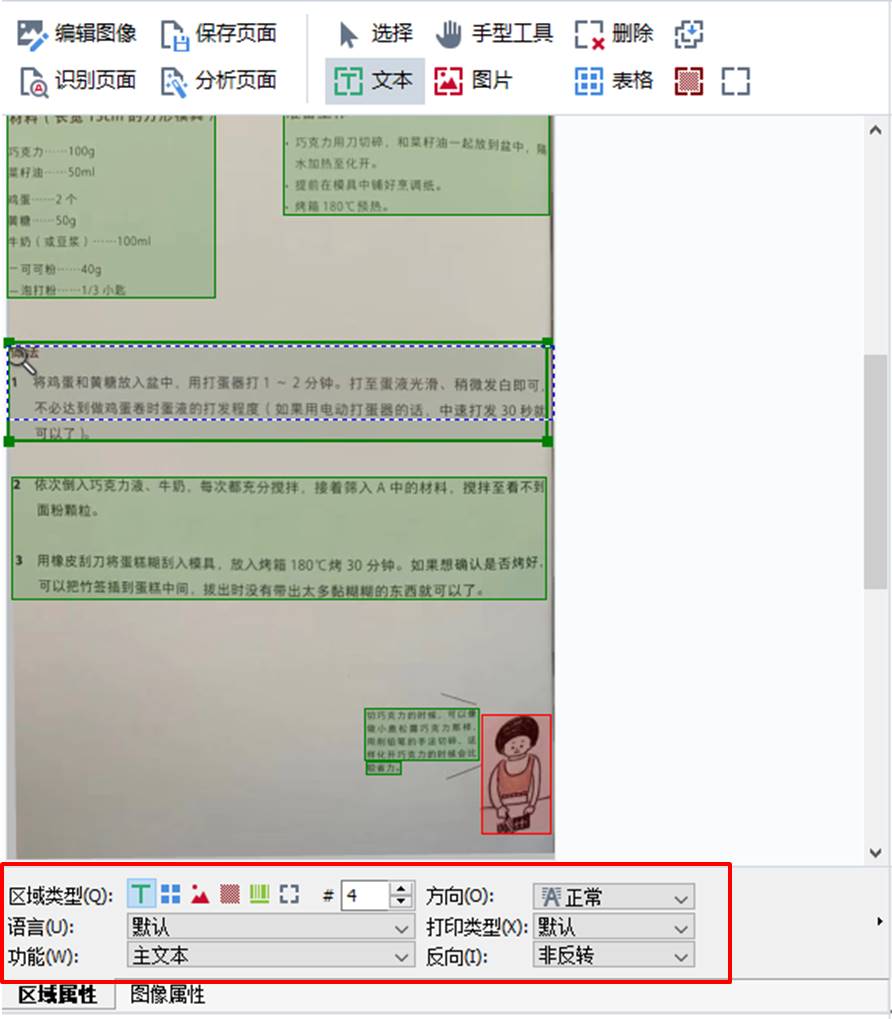
三、快速查找错误字符
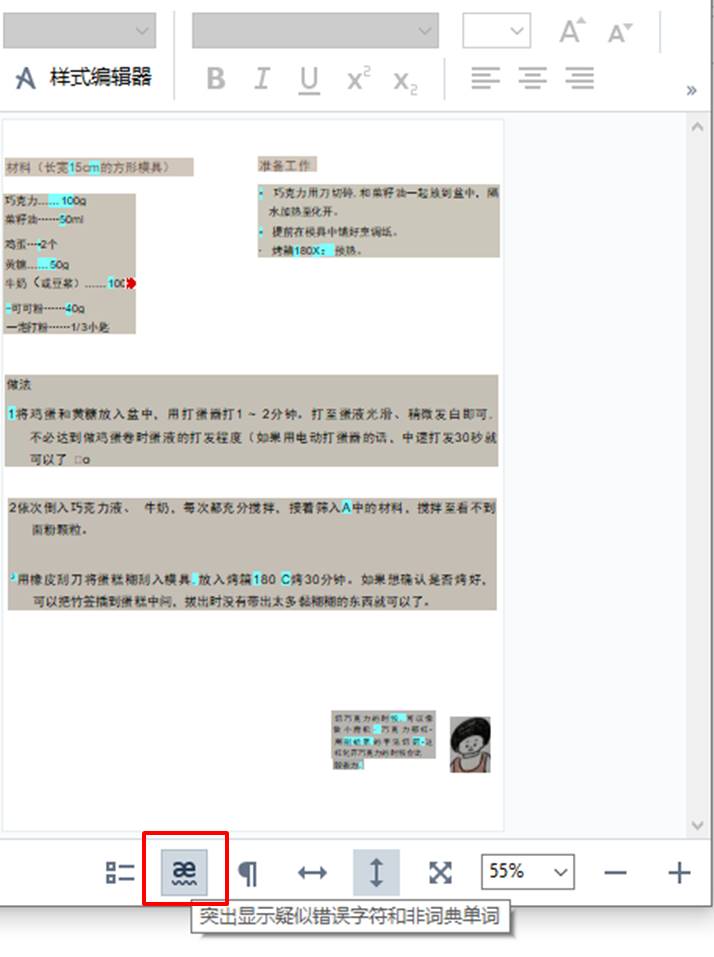
如果所需识别的图像包含大量文本时,我们如何才能快速地检查文本识别的准确度?实际上,ABBYY FineReader PDF 15已为我们提供了便捷的检查功能。
如图8所示,单击文本编辑面板底部的“突出显示疑似错误字符”按钮,即可标亮一些疑似错误的字符,实现快速检查的目的。
四、小结
综上所述,ABBYY FineReader PDF 15提供的OCR文本识别功能,不仅能帮助我们识别图像上的文本,而且还提供了多项便捷的功能辅助文本识别。
比如,通过使用图像预处理功能,可纠正一些拍摄失误;通过使用手动区域设置功能,可灵活地设置文本识别的区域等。
作者:泽洋
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

ABBYY如何使用 ABBYY支持哪些输出格式
ABBYY FineReader是一款非常优秀的PDF转换工具,不仅支持超百余种语言的文字识别,还能将扫描件、PDF或图片内容快速提取并转换为可编辑的格式,对我们的学习、工作非常有帮助。接下来本文将详细为大家介绍ABBYY如何使用, ABBYY支持哪些输出格式的相关内容,助力大家快速上手ABBYY FineReader文字识别软件。...
阅读全文 >

ABBYY怎么对齐图片 ABBYY图片怎么转向
ABBYY FineReader是一款专业的OCR文字识别软件,除了支持PDF文件、图片、扫描件中的文字识别之外,还可以对于图片上的内容进行整句整段的纠正,甚至调整方向,下面我们就来为大家演示一下ABBYY怎么对齐图片,ABBYY图片怎么转向的相关内容。...
阅读全文 >

PDF文件搜索不了文字怎么办 ABBYY怎么搜索PDF文字
工作中收到的PDF文件少则十几页,多则几百页,如果想要通过检索关键字来准确锁定信息位置,往往很难实现,每一次收集关键信息,都要从头开始浏览PDF文件,浪费了大量的时间。想知道PDF文件搜索不了文字怎么办,ABBYY怎么搜索PDF文字?不妨借助实用工具处理这些问题,下文提供了解决思路,学会这些让办公事半功倍。...
阅读全文 >

ABBYY怎么提高识别率 ABBYY怎么增加准确度
很多小伙伴反馈,在使用ABBYY FineReader软件进行文字识别的时候发现识别率比较低,想提高文字识别的准确度,但却不知道该怎么操作,为了方便大家能更好的使用ABBYY FineReader软件,下面我将来带大家了解一下ABBYY怎么提高识别率, ABBYY怎么增加准确度的相关内容。...
阅读全文 >


