发布时间:2015-09-22 16: 17: 43
作为ABBYY OCR产品识别技术的开发人员,笔者将以ABBYY最有名的识别技术软件FineReader为例来解读现代OCR技术的专业用途。
笔者认为的“技术”是什么意思呢?——有时候,所有的技术模块(软件可见的终端用户的部分)都包含在“识别引擎”这个定义之中,这并不完全正确:这些模块不仅识别字符,还有其他的功能,我将在后文中加以介绍。
FineReader软件有哪些功能?
目前任何电脑端FineReader版本都可以自动完成所有步骤:从使用扫描仪或相机拍摄图像开始,或从图像文件开始,到将处理结果导出为某种 文件格式或导出到指定软件之中,都不需要用户在屏幕上进行操作。该程序自身能够“识别”(笔者沿用了这种说法,因为FineReader会定义文本段落和 图片的位置,对图像中的图像文字部分进行OCR处理,生成一个文件,并将该文件保存为用户指定的文件格式)出用户的全部需求。
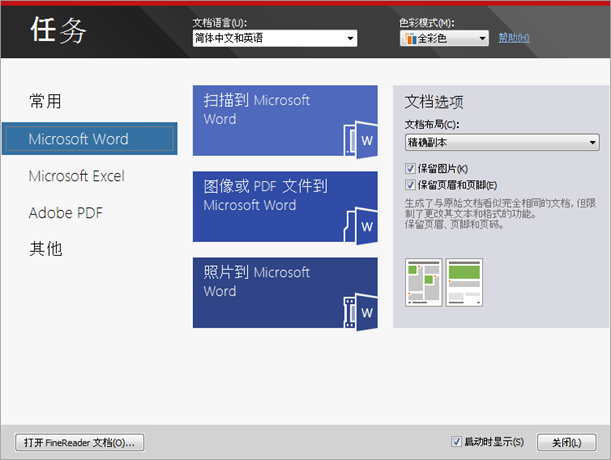
那么,用户需要做什么呢?
事实上,用户通常什么都不用做:他(她)只需要给软件下达指令,然后就可以得到结果了。有时用户不满意自动处理的结果,但用户通常会这样想:“真倒霉…算了。”
不幸的是,他们有些人并不知道,除了运行程序时显示的“快速任务”窗口,还可以通过若干其他方法来管理软件的性能。这些方法借助人类智慧,能够克服该程序在人工智能方面的缺陷和不足(有时候是根本性的缺陷)。
如何才能学会这些方法呢?下面几种途径都是可行的,必要时可以结合使用多种途径:
· 阅读简短的《用户手册》、《用户手册》全本和在线帮助——它们无疑都很长,但它们相当有用。
· 通读这篇文章。它简短得多,而且作者保证会消除用户对该软件的恐惧,唤醒他们的兴趣,让他们去体验这款软件。
试用该程序(您无法绕过这个阶段)——即便是通过免费试用版,您也可以体验下述实际应用所需的每项功能。
如何开始?
首先,您应该养成习惯,将文档不仅保存为最终需要的格式,还要保存为FineReader文档格式。这样,在处理大型文档时,您不必一步到位, 而是可以分步进行,等方便的时候再回头处理已经识别和核对过的文件,进行自定义导出设置等操作。所有FineReader文档操作都整合在“文件”菜单 中。
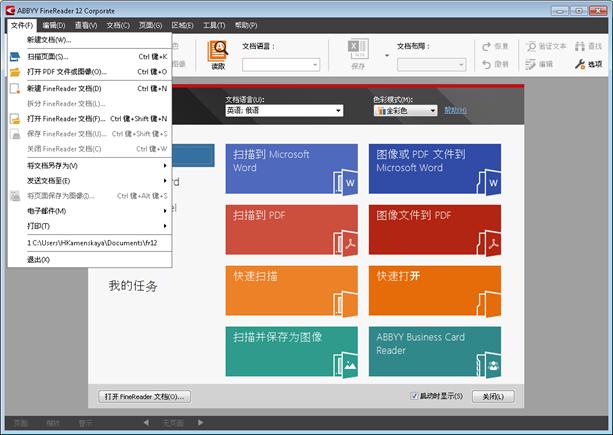
没有什么比一个好的理论更实用了,或者说“识别”包含哪些流程
看着那些简短的快捷任务名,如“扫描到PDF”,您很难想象,“扫描”和“PDF”之间涉及多少流程(也就是“到”的含义)。让我们来细探究竟。“将光栅图像转换为可编辑文本”(不只是“识别”)任务包含着以下几个主要步骤:
1. 获取单页或多页图像(从扫描仪、相机或文件获得),将其转换成特殊的内部格式,以简化和加速后续操作)。总之,此时程序使用了图像处理子系统,这个系统可以识别、读取和编辑众多的外部格式。
2. 准备图像(失真校正,将双页图像分割成单页,这些都可在“选项”菜单中定制),这也是由图像处理子系统完成的。
3. 分割或页面布局分析。当确定要识别哪些内容以后,分析子系统会进行分割或页面布局分析。
4. 识别(终于到这一步了!)。由识别子系统(真是个巨大的惊喜,不是吗?)完成。它会生成由若干片段(未来的单词)组成的文本字符串,片段中包含若干无格式 符号(甚至没有分段,只有文本字符串)。如果您对技术细节非常感兴趣,那么可以告诉您,除了所有其他组件,识别子系统还采用了词法子系统和可训练识别机 制,它可以识别FineReader不认识(有时会出现这种情况)的装饰字体和符号。
5. 文件合成(它包括两个阶段:对于页面来说,在识别完单页以后开始;对于文件来说,它是在识别完所有页面之后开始)。正是在这个阶段,定义了文字(除了符号代码)布局和整体结构,生成了整个文件 。这是由合成子系统完成的。
6. 预览和编辑页面图像、区域结构、和识别结果,由Program Cover(程序封面)和编辑子系统完成(可执行文件FineReader.exe就是这个cover)。您可以查看和编辑处理过程中产生的大量信息(从 块结构开始)。当然,用户并不能编辑各个子系统生成的所有信息。最主要的原因是,要显示出自动过程中找到的所有信息,以及它们的功能和关系,用户接口会变 得非常复杂,使用起来很不方便。
将生成的文档转换成各种外部格式,是由导出子系统(这正是我的专长所在)来完成的。在导出之前,子系统并不知道处理结果要导出为哪种格式,或采 用哪种导出方案。因此,文件合成时会同时生成各种导出格式/变体可能需要的若干方式,而Cover会将它们显示出来,就像结果在合适软件中显示的那样。这 会给开发过程带来很大的麻烦:由于相关子系统之间联系紧密,当某个漏洞或功能处于两个子系统的边界之时,职责划分会变得复杂。但我们可以处理这种情况。
为什么有这么多的模块(子系统)?
我们首先要强调的是,笔者在这里只列出了重要的模块,还有一些模块没有列出。例如,扫描子系统的开发过程不是一两天的事情,而是积年累月的过程。不过我们还是说回正题。
首先,10多年来,大批人员开发了“识别技术”项目,并在此基础上开发了众多复杂产品:他们的工作需要进行结构和技术区分,使各自的开发具有或多或少的独立性,同时又能详细地描述各个过程以及其衔接规则,以便它们能够在逻辑上交互配合。
其次,有些产品并没有采用所有的处理阶段(以及实现它们的子系统),只是采用了其中部分阶段。例如,识别子系统具有其自身的印刷和手写文字识别 子模块,每个子模块又有下属子模块,如处理复杂语言的下属子模块。这种情况与条形码识别模块以及几种图像格式编解码器类似 :有些产品完全不需要它们。

结果是什么?为什么用户需要它?
如果您不留心这个问题,即便完全正确的OCR结果也可能会让您不满意:此时所有的字符都被找到并正确识别出来,但总体来说,结果并非您所期望的那样。下面我来列出运用FineReader及其功能的常见情况。
将映像文件档案转换成数字格式,在一定程度地保留布局的同时,更轻松地搜索和引用文字片段
在这种情况下,通常将经过处理的文档转换成PDF文件,既保留可见的页面图像(可能并非原始状态,但尽量接近原始状态),同时增加隐藏的识别文 字层,您可以在各种PDF查看器中搜索、突显、摘引和复制文字。这种存储文件称为“双层PDF”,它是流行的格式,但此外还有其他三种格式。我将在以后 的文章中介绍所有其他格式。熟悉DjVu格式的用户也可以使用类似的存储模式。
“图像遮盖文本”模式的主要优点是,它不需要太多有关被保存文本的结构信息,因为它只是使用原始图像上的坐标信息,将符号和页面的确切位置联系 起来。因此,如果表格没有被准确地自动检测出来(即将它们分成多个毫无关联的文本字符串),或者文本形成不合逻辑的段落,这都无关紧要:反正您能够找到全 部或绝大多数所需信息;重要的是,字符被正确识别出来了,构成了正确的单词。
利用任何一种常用的文字编辑器,创建类似于原件的格式文件(Microsoft Word、Open Office、LibreOffice Writer等), 以便对新文件中的大段文字进行后续编辑和重复使用。
保存为RTF、DOCX(针对MS Word)和ODT(针对Writer)格式时支持四种配置,它们彼此各不相同,或侧重于“精确保留原始布局”,或侧重于“易于编辑和修订内容”。日后我 将详细介绍它们之间的差异,但要得到理想的处理结果,关键在于,FineReader要正确地解读文档的布局,理解各个区块及其特性。
扫描纸质书籍来制作电子书
这非常类似于前一种方案,但由于电子书格式文件通常要简单得多,其编辑方法更有限,经过FineReader处理之后查看更为复杂,有时需要更多地关注某些功能。
这些知识有什么用?
您可能已经知道了,理解所有这些合乎逻辑但逻辑不那么明显的细节,用户就能更轻松地获得(从用户的角度来讲)的FineReader处理结果。
更多关于ABBYY FineReader的相关信息,可点击进入ABBYY中文服务中心,查看您需要的信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:
文字识别扫描工具有哪些 如何文字识别扫描文件
平时办公整理资料时,总会遇到一堆纸质文件、扫描件,想把里面的文字提取出来编辑,手动打字又慢又容易错。这时候文字识别扫描工具就派上大用场了,不管是简单的图片文字提取,还是复杂的扫描PDF识别,都能轻松搞定。下面就给大家介绍一下文字识别扫描工具有哪些,如何文字识别扫描文件的相关内容。...
阅读全文 >

ABBYY图片转为Word乱码 ABBYY怎么将图片转换文档
把图片转成可编辑的Word文档时,不少用户都会用ABBYY FineReader这款OCR工具,但偶尔也会碰到转换后乱码的情况,要么文字错乱,要么符号显示异常。其实这些问题很好解决,今天就详细为大家介绍一下ABBYY图片转为Word乱码,ABBYY怎么将图片转换文档的相关内容。...
阅读全文 >

OCR文字识别是人工智能吗 OCR文字识别软件怎么操作
在日常工作和学习中,我们经常会遇到需要将图片、扫描件中的文字提取出来的情况,这时候ABBYY FineReader的OCR文字识别技术就派上了用场。不少人可能会好奇,OCR文字识别是人工智能吗,OCR文字识别软件怎么操作?为了解决大家这些疑问,接下来我们就围绕这两个问题展开介绍。...
阅读全文 >

怎样用ABBYY优化扫描件 ABBYY图像增强操作
在职场办公中,各部门经常会用到PDF文档,有时甚至需要将纸质文件扫描成PDF,但扫描后的文件经常出现文字模糊、页面歪斜或黑边等问题,其实,这些问题通过ABBYY FineReader软件都可以轻松解决。下面就一起来看看怎样用ABBYY优化扫描件,ABBYY图像增强操作的相关内容。...
阅读全文 >


