发布时间:2017-06-08 11: 36: 47
ABBYY FineReader 14OCR文字识别软件识别文档时使用与文档语言有关的数据,程序在识别有些包含不常见元素(如代号)的文档里的字符时可能会出错,因为文档语言可能不包含这些字符,要识别这样的文档,可以创建一种包含这些必要字符的自定义语言,还可以创建OCR语言组,在识别文档的时候使用这些语言组。
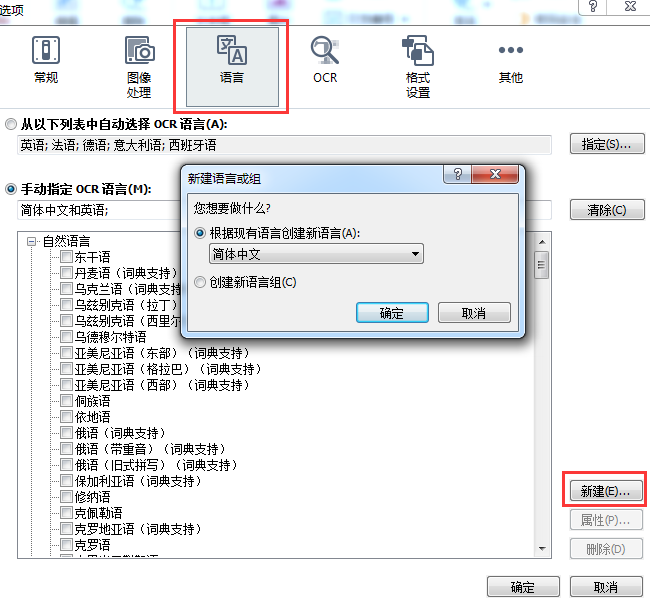
1、打开‘选项’对话框(工具 > 选项),点击‘语言’选项卡。
2、点击‘新建’按钮。
3、在打开的对话框中,选择‘根据现有语言创建新语言’,然后选择你想用作为新语言基础的语言,点击‘确定’。
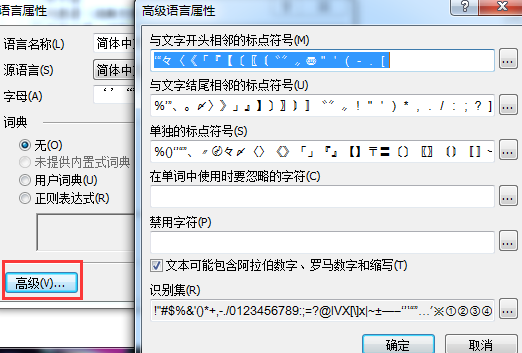
4、语言属性对话框将打开,在该对话框中:
a、为新语言输入一个名字。
b、在新语言或语言组对话框中选择的语言将显示在源语言下拉列表中,可以从该下拉列表选择不同的语言。
c、‘字母’项包含基本语言的字母表,如果想编辑字母表,则点击 按钮。
按钮。
d、词典选项组包含词典的一些选项,为程序识别文本,检查结果时所用。
e、语言可以有很多额外的属性,若要更改这些属性,点击‘高级’按钮来打开高级语言属性对话框,在这里指定语言属性:
5、选择OCR语言时,现在就可以选择新建的语言了。
默认情况下,用户语言保存在OCR项目的文件夹里,你也可以将所有用户样式和语言保存为单一的文件(打开‘选项’对话框,点击‘OCR’标签,然后点击‘保存样式和语言’按钮。)
如果需要定期使用特定的语言组,你可能希望将这些语言分组到一起,以便操作:
1、打开‘选项’对话框,点击‘语言’选项卡。
2、点击‘新建’按钮。
3、在‘新建语言或组’对话框中,选择‘创建新语言组’选项,然后点击确定。
4、语言组属性对话框将打开,在该对话框中,为语言组指定一个名字,然后选择要添加到语言组里的语言。
如果你知道你的文本不包含某些字符,你可能会明确地指定这些所谓的禁用字符,这样做可以提高OCR的速度和准确度。若要指定这些字符,点击语言组属性对话框中的‘高级‘按钮,在‘禁用字符’字段输入禁用的字符。
5、点击确定。
新的语言组将出现在主工具栏的语言下拉列表中。
1、在主工具栏上,从语言下拉列表中选择‘更多语言’。
2、在语言编辑器对话框中,选择‘手动指定OCR语言’选项。
3、选择需要的语言,然后点击确定。
有关ABBYY FineReader 14的更多内容,请点击访问ABBYY教程了解更多信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

abbyy finereader需要付费吗 abbyy软件有免费的吗
ABBYY是一家全球领先的技术公司,专注于开发和提供智能文档处理和数据捕获解决方案。ABBYY的主要产品包括ABBYY FineReader,这是一款流行的OCR软件,可将扫描的文档和图像转换为可编辑的文本格式。...
阅读全文 >
Word转PDF怎么不分页 Word转PDF怎么保留导航
有许多平台上传文件时都不能直接上传文档格式,而是要求上传PDF格式,然而PDF格式的文件又不能直接进行编辑,因此我们需要将Word文档格式转换成PDF格式之后才能提交。但这也引发了一系列的问题,例如转换成Word文档后存在空白页、转换后格式发生变化等情况,今天我们就来说一说Word转PDF怎么不分页,Word转PDF怎么保留导航。...
阅读全文 >
PDF怎么压缩文件大小 PDF怎么压缩到又小又清晰
PDF是我们比较常见的文件类型,现在许多平台在上传文件时都会要求上传PDF格式。但是如果我们的PDF文件超过了平台的限制会导致上传失败,这对于许多人来说是一个十分头疼的问题,那么我们今天就来说一说PDF怎么压缩文件大小,PDF怎么压缩到又小又清晰。...
阅读全文 >

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >


