发布时间:2021-01-22 10: 34: 02
遇到一些好的网页介绍,很多人都会习惯将内容截图下来,便于后续参考。但如果有选择的话,更多人会希望将网页内容以文档的方式保存。但我们知道,简单地复制粘贴网页内容,只能获取到一堆“乱文”。
其实,我们可以将网页截图下来,然后使用ABBYY FineReader PDF 15的高级转换功能,直接将网页截图转换为PDF文档。这么神奇的功能,该怎么操作呢?接下来,一起来看看吧。
一、打开网页截图
首先,我们需要打开目标网站进行截图的操作。如果您需要截取的网页比较长,且超过一屏显示的话,建议使用滚动截图软件。
二、在OCR编辑器中打开截图
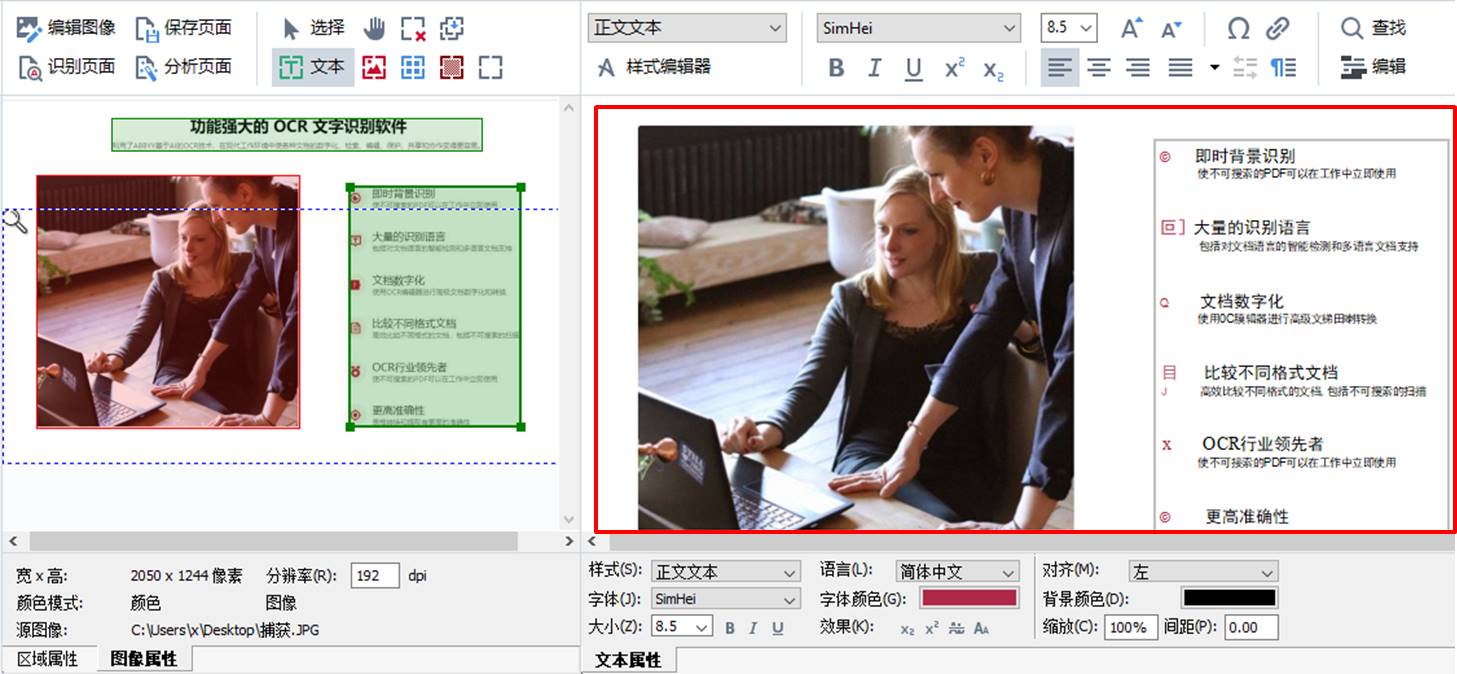
完成网站的截图后,就可以打开ABBYY FineReader PDF 15软件,并单击“在OCR编辑器中打开”选项,使用其图像高级转换功能。

完成图像的识别后,如图3所示,在OCR编辑器左侧的区域属性面板中,可以看到,ABBYY FineReader PDF 15已准确识别了文本区域与图片区域。
而在右侧的文本编辑区域,可以看到,文本的识别准确性相当高,基本无识别错误的文本。
三、编辑文本
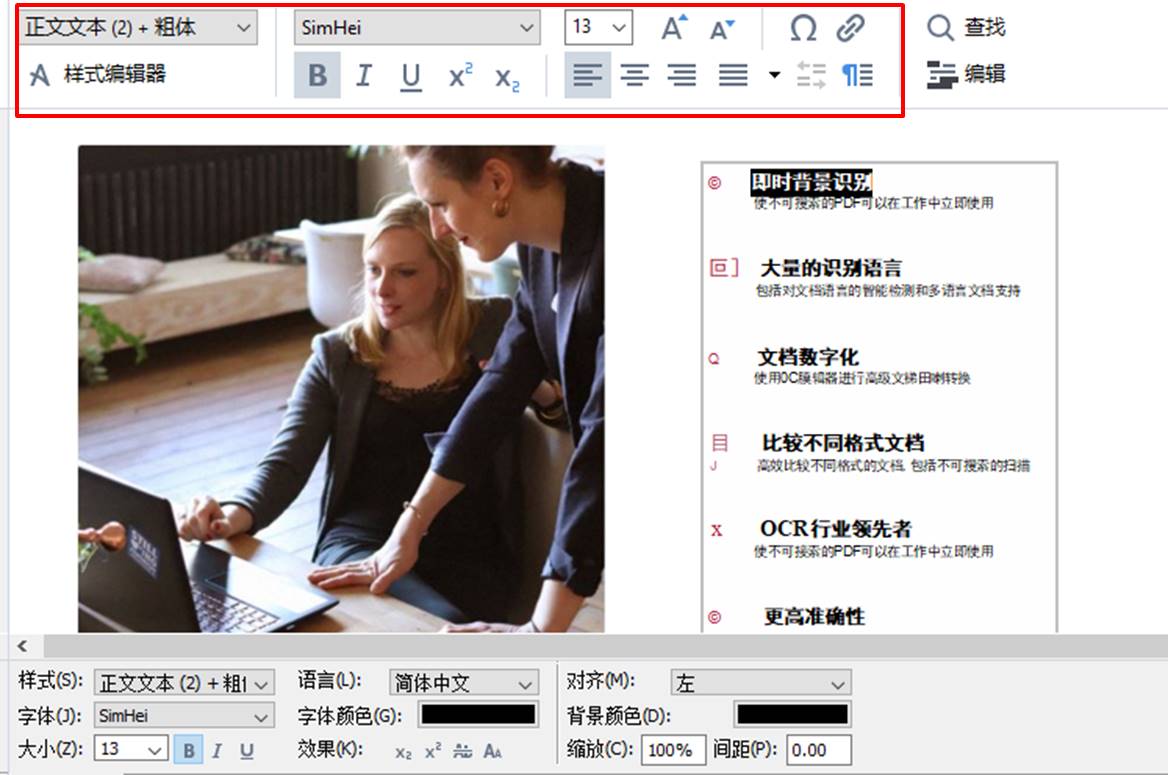
除了检查文本识别的准确性外,我们也可以使用ABBYY FineReader PDF 15 OCR编辑器中的文本编辑功能,编辑识别后的文本。
比如,如图4所示,使用加粗功能,加粗网页中的标题文字,并修正一下文字的对齐问题。
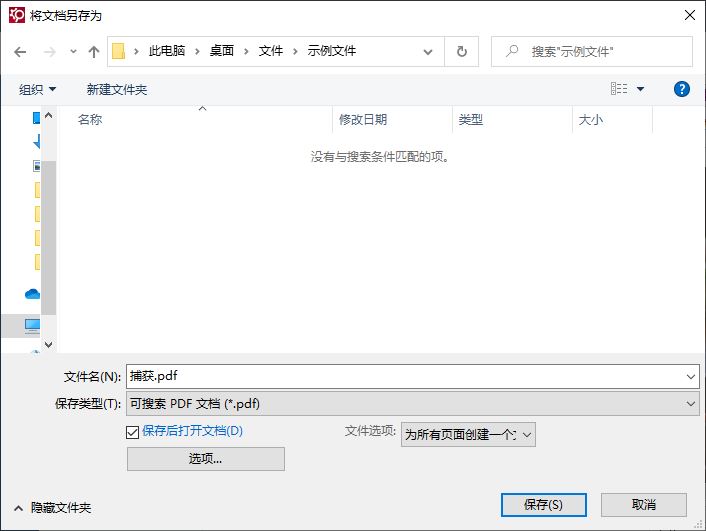
四、另存为PDF文档
完成文本的编辑后,就可以使用编辑器上方的保存功能,将识别后的文本保存为PDF文档。除了PDF文档外,还可以将识别后的文本保存为Word文档、Excel电子表格等格式。
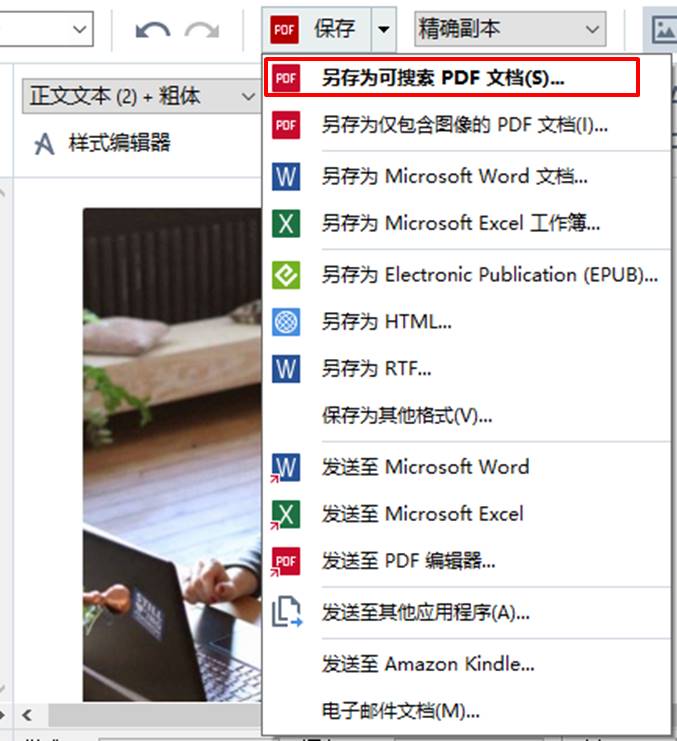
单击保存按钮后,指定文档保存的位置以及保存的名称。
打开保存后的PDF文档,可以看到,文档很好地“复刻”了网页的内容,使用起来相当简单、快捷。
四、小结
通过应用文字识别软件ABBYY FineReader PDF 15的高级转换功能,我们就能快速地将网页内容转换为PDF文档、Word文档等格式,简单方便,再也不需要将大量的时间浪费在复制文本、保存图片、排版格式上,一键就能复刻网页。
作者:泽洋
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

ABBYY怎么提取PDF表格数据 ABBYY如何识别复杂表格
在日常工作中,我们经常会遇到需要复制PDF文档中表格的数据到Excel中的情况,特别是在处理财务报表过程中,如果直接将PDF表格中的内容进行复制粘贴,很容易出现数据错误。接下来我们将通过ABBYY FineReader OCR文字识别软件为大家演示一下ABBYY怎么提取PDF表格数据,ABBYY如何识别复杂表格的相关内容。...
阅读全文 >

PDF怎么对比两篇文章不一样 ABBYY文档比较功能怎么用
在日常工作中,我们经常会遇到需要对比两份PDF文档差异的情况,手动逐字逐句比对不仅耗时耗力,还容易遗漏细节。尤其当文档内容包含大量表格时,这会严重影响我们的工作效率,今天我们就借助ABBYY FineReader来带大家了解一下PDF怎么对比两篇文章不一样,ABBYY文档比较功能怎么用的相关方法。...
阅读全文 >

如何把PDF合并到一起 多份PDF如何拼接成一份
在进行PDF文件编辑操作时,为了有效简化文档管理,提高工作效率,我们往往会将多个pdf合并成一个,但还有部分小伙伴不知道如何把pdf进行合并操作,今天这篇文章将带大家了解一下如何把PDF合并到一起,多份PDF如何拼接成一份的合并方法,简单几步就能完成,一起来学习下吧。...
阅读全文 >

OCR识别应用有哪些 OCR识别对象的文件类型
OCR(光学字符识别)是针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。那OCR识别的应用有哪些呢?下面一起来了解ocr识别应用有哪些,ocr识别对象的文件类型的相关内容。...
阅读全文 >


