发布时间:2021-07-16 11: 16: 37
OCR文字识别工具我们经常用,但提到市场上哪个软件做的比较好,相信很多人脑海中第一时间浮现的就是ABBYY FineReader PDF 15软件,软件识别率高,功能强大,不仅能够识别、转换文档,还能编辑修改文档,受不少人喜爱。
相较于普通文档的识别,扫描版繁体文献识别难度更大,但很多研究员和相关专业学生却对扫描识别繁体字有非常大的需求。今天小编教大家如何使用ABBYY FineReader PDF 15识别繁体文献资料。
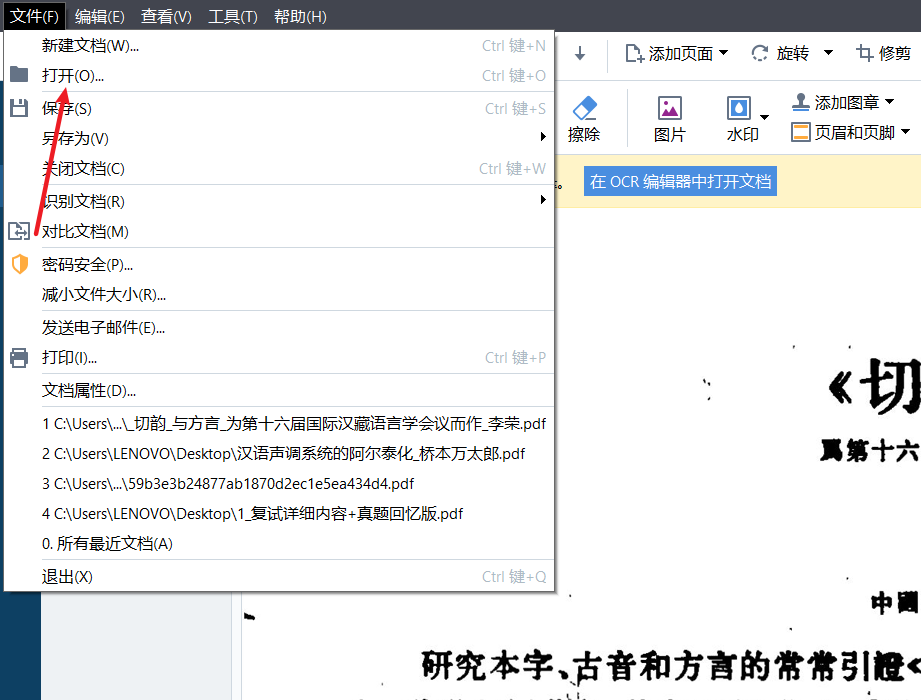
首先,大家需要将保存为PDF格式的繁体文献资料保存在电脑内,点击打开pdf文件功能键,即可打开文档。
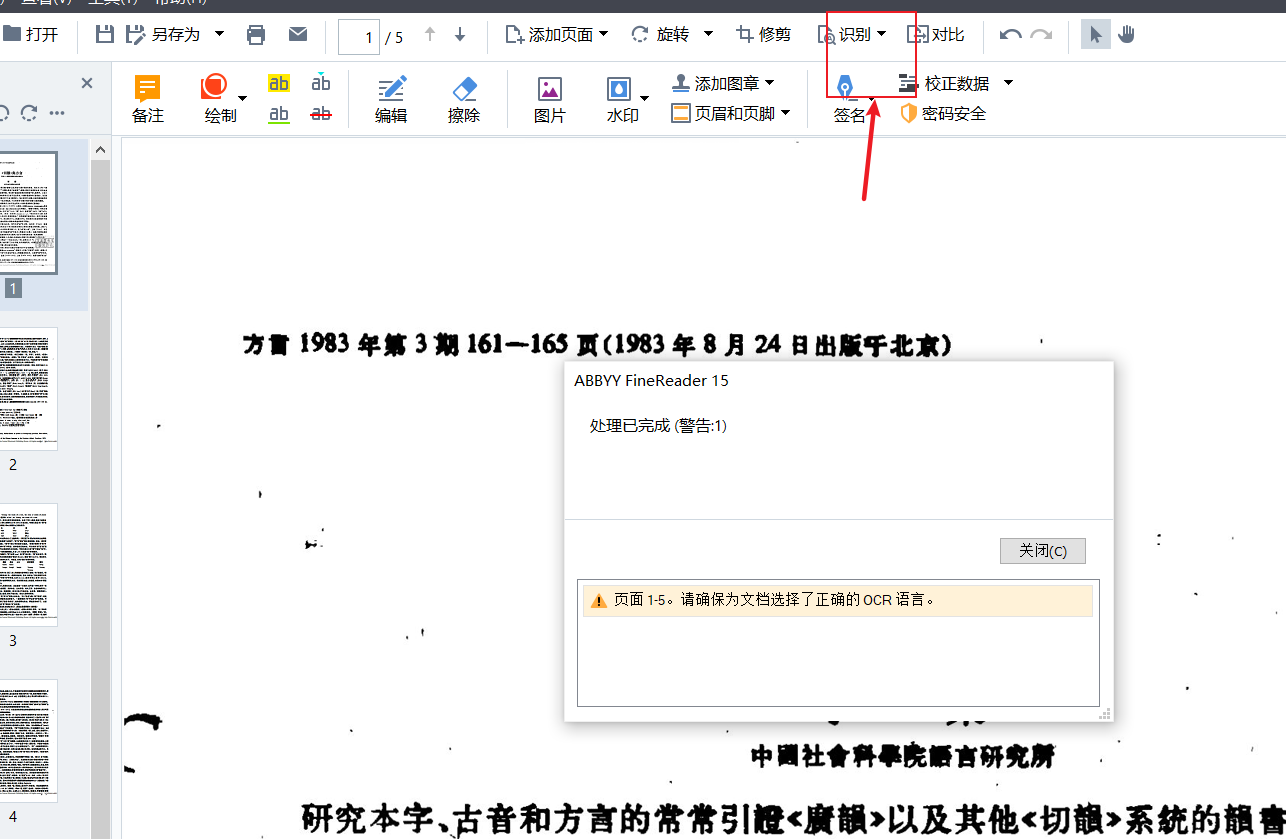
打开文档后,点击软件页面识别功能键即可对繁体文档文字进行识别。
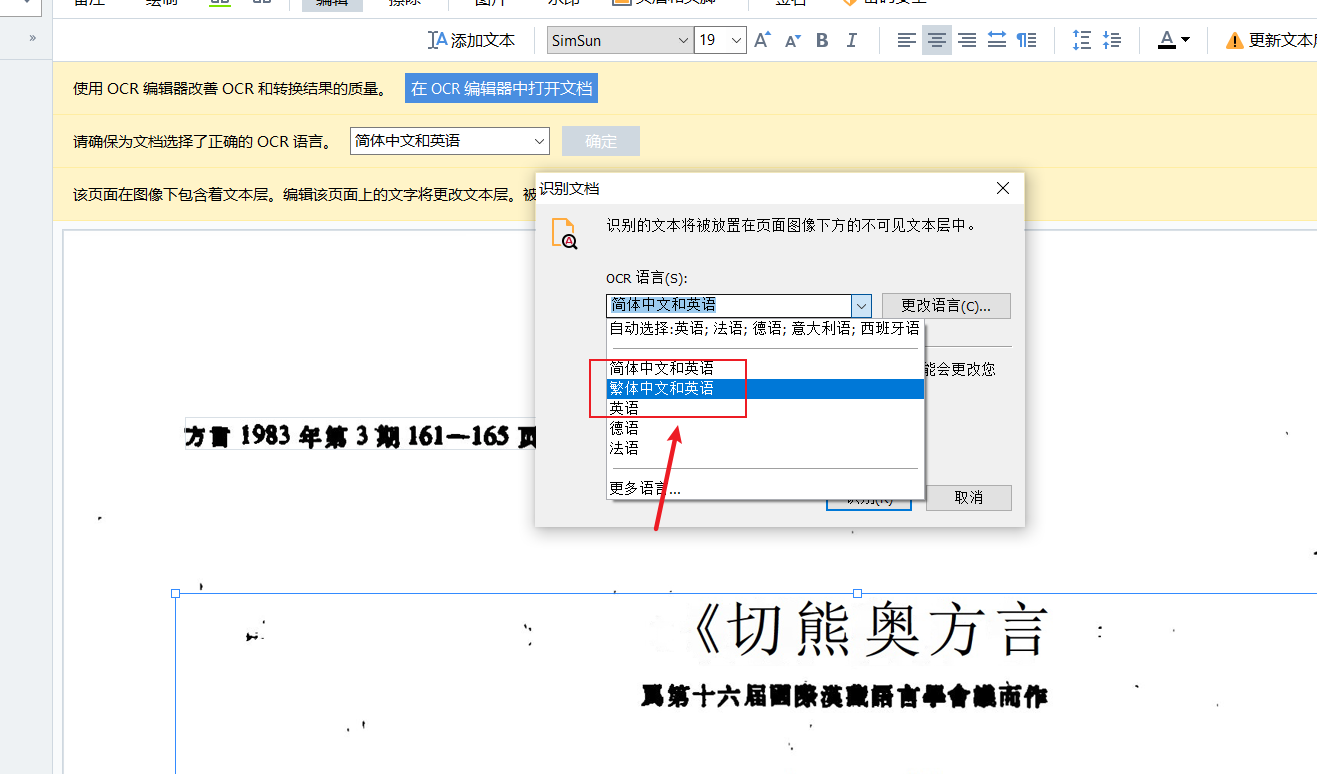
需要注意的是,因为识别的是繁体字文档,所以点击识别功能键后,我们需要在弹出的窗口上点击更改语言,将其切换为繁体中文。点击识别按钮,等待一段时间,文档即可完成识别。
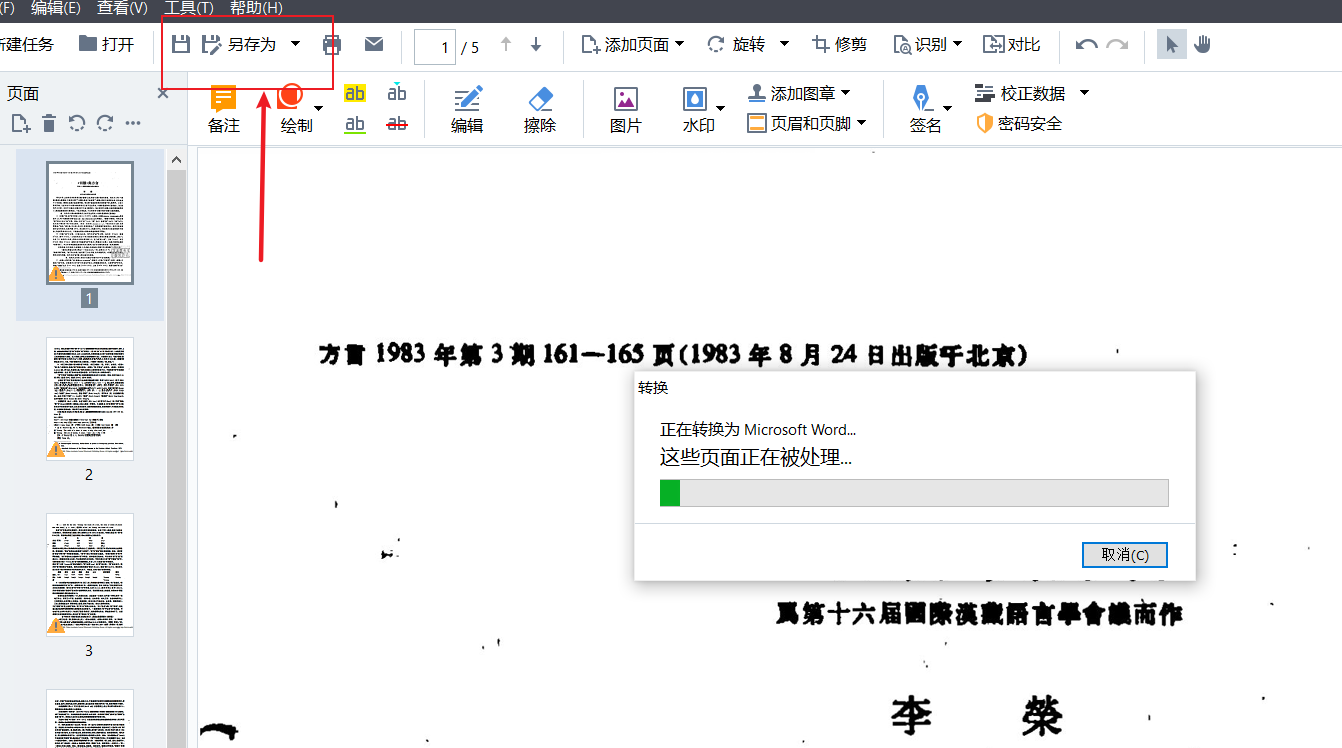
ABBYY FineReader PDF 15识别文档后,点击另存为功能键,可以将文档保存为其它格式。
软件格式可选择性非常多,既可以保存为Excel、word,也可以保存为html等格式。为了方便编辑修改,我们在识别繁体文档后,一般将其保存为word格式。
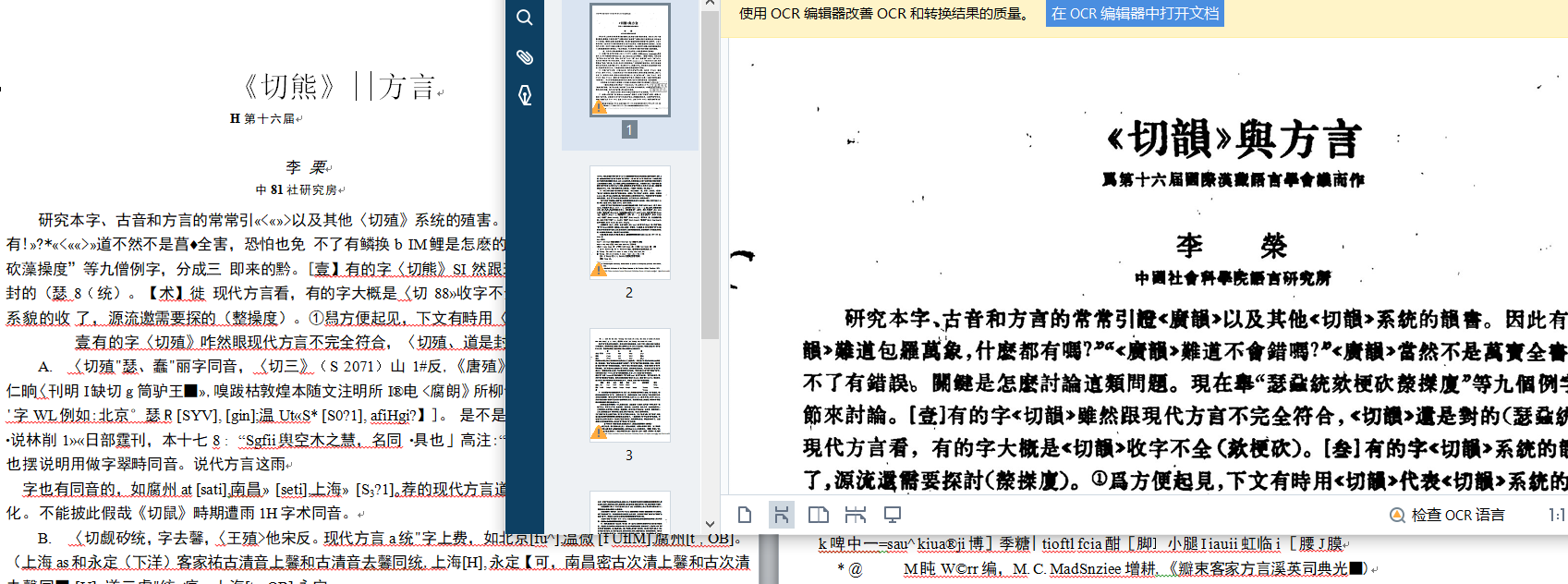
点击保存后,打开word文档,我们就可以检查繁体字文档识别效果了,一些繁体文献在被扫描为PDF格式时,因为文献本身文字模糊不清,ABBYY FineReader PDF 15软件可能无法识别这些字。所以软件识别繁体字文献的错误率可能比一般文献稍高。
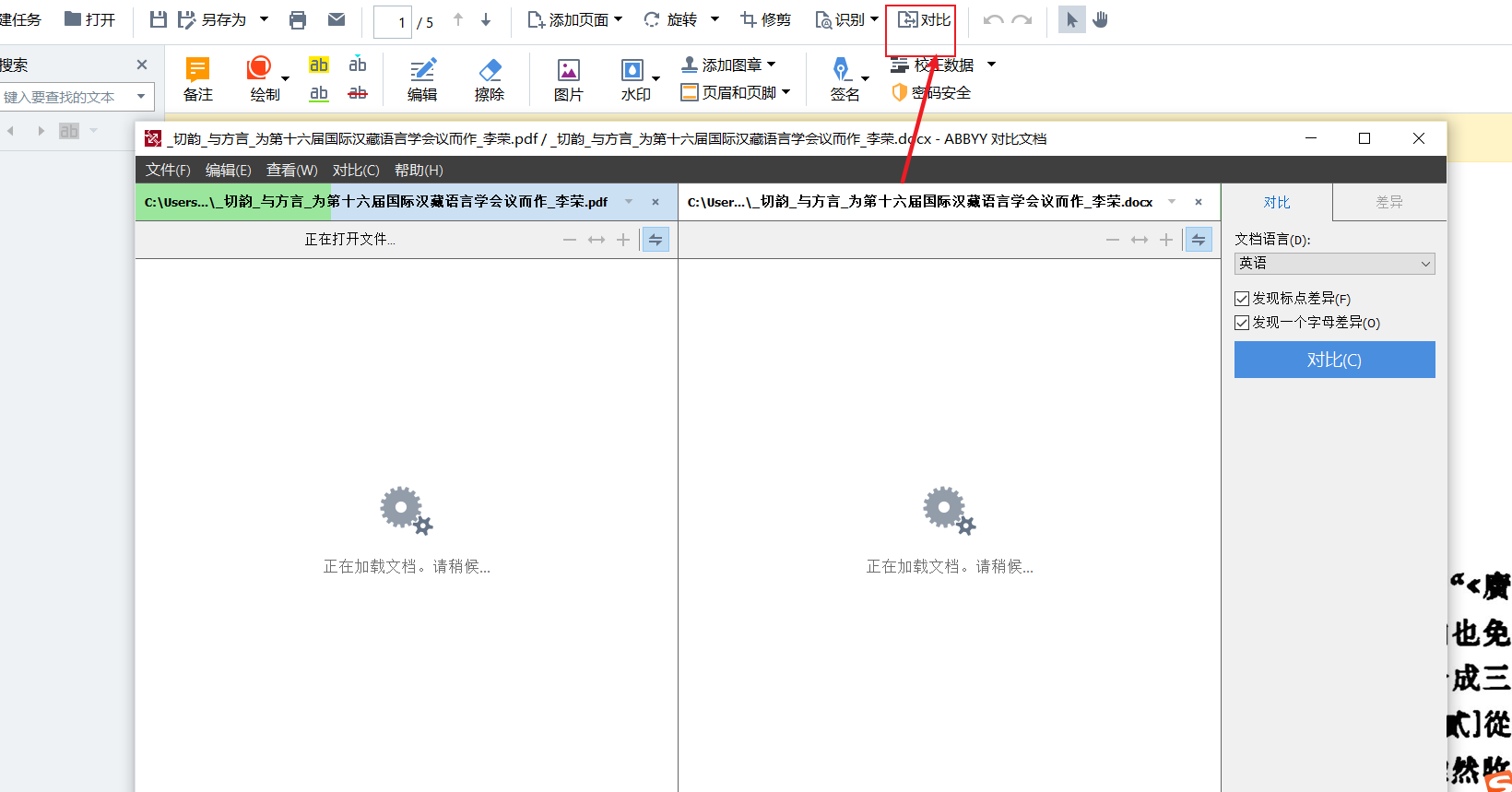
为了减少错误,我们可以利用ABBYY FineReader PDF 15对比功能核对pdf和word文档之间的差别。点击对比功能键,在页面右侧导入已经转化为word格式并保存在电脑内的文档,点击对比按钮,软件经过分析后,会自动识别两份文档之间的不同之处,方便我们修改。
对于文字研究工作者而言,ABBYY FineReader PDF 15的识别修改繁体文献还是非常方便的,如果大家有文字识别需求,欢迎到中文网站了解更多功能。
作者 若水
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

ABBYY怎么提取PDF表格数据 ABBYY如何识别复杂表格
在日常工作中,我们经常会遇到需要复制PDF文档中表格的数据到Excel中的情况,特别是在处理财务报表过程中,如果直接将PDF表格中的内容进行复制粘贴,很容易出现数据错误。接下来我们将通过ABBYY FineReader OCR文字识别软件为大家演示一下ABBYY怎么提取PDF表格数据,ABBYY如何识别复杂表格的相关内容。...
阅读全文 >

ABBYY可以去水印吗 如何用ABBYY去除图片水印
在使用PDF的过程中,我们经常会碰到带有水印的PDF文件,这些水印会在我们阅读过程中造成一定的干扰,遇到这种情况该怎么办?ABBYY可以去水印吗,如何用ABBYY去除图片水印,接下来我们就一起来了解下有效去水印的操作方法。...
阅读全文 >

图片识别文字的方法有哪些 图片识别文字用什么软件
当我们看到图片中包含有重要的文字内容时,我们都会下意识地将图片中的文字提取出来,然后再对其进行编辑,那有没有办法可以快速识别图片中的文字呢?今天我们就一起来探索一下图片识别文字的方法有哪些,图片识别文字用什么软件的相关内容。...
阅读全文 >
pdf编辑文字为什么会消失 pdf编辑文字不支持type3字体怎么办
PDF文档编辑是我们工作中的重要内容之一。作为一款专业的PDF编辑、阅读软件,ABBYY FineReader能够帮助我们提高工作效率。然而,在使用软件的过程中可能会遇到一些问题,例如:PDF编辑文字为什么会消失,PDF编辑文字不支持type3字体怎么办?接下来我就来为大家解答这两个问题。...
阅读全文 >


