发布时间:2021-10-15 14: 05: 45
我们每天都要和各种各样的文档打交道,有时候,我们需要保存文档中的一部分内容,但是我们会发现,在PDF文档中,我们并不能直接保存文档中的图片或者表格,带来了诸多不便。而如果我们如果想要将PDF文档中的图片和表格保存下来的话,那么就需要用到这款OCR文字识别软件——ABBYY Finereader 15。
以本台电脑为例,本台电脑采用的是Windows10系统,软件版本为ABBYY Finereader 15 corporate。我们打开软件主界面之后,点击“打开”-“打开OCR编辑器”,选中自己想要打开的文档即可进入到我们需要操作的界面了。
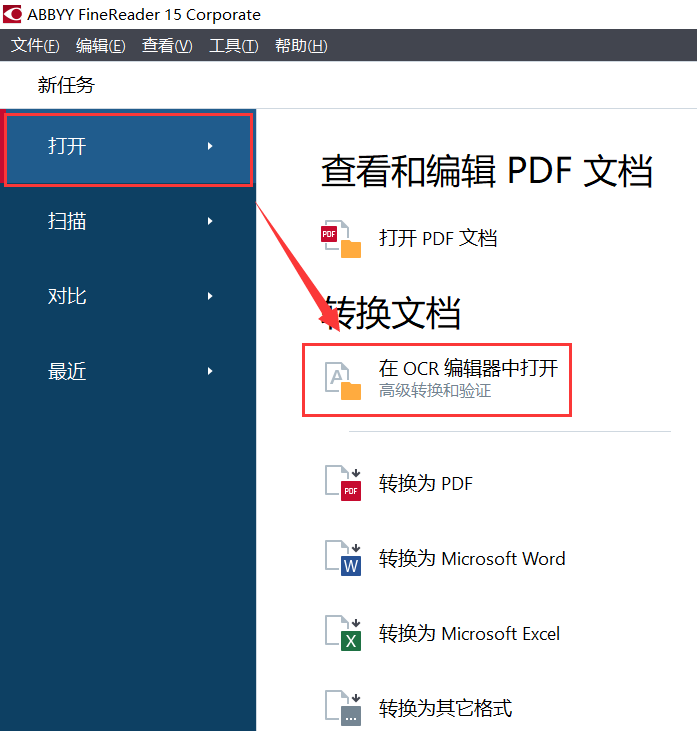
在开始介绍如何保存PDF文档中的表格之前,先提醒一下,当我们打开OCR编辑器之后,首先需要识别页面,否则接下来的所有操作都无法进行。我们找到并点击上方工具栏中的“识别页面”,稍等片刻软件就会对PDF文档进行自动识别。
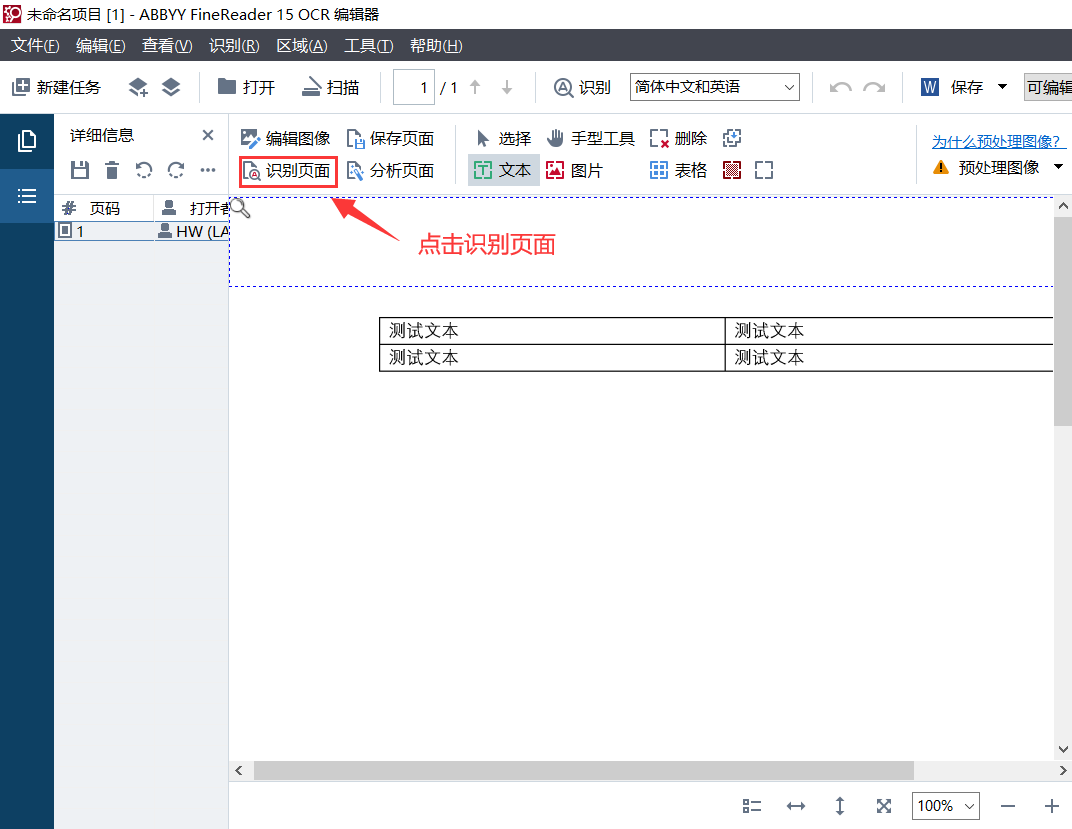
在识别页面完成之后,我们就可以正式开始操作了,我们在OCR编辑器中会看到一个虚线方框,将此虚线方框拖动至我们需要保存的表格处,随后点击“保存页面”,我们只需要选择保存的位置即可完成保存PDF文档中表格的操作。
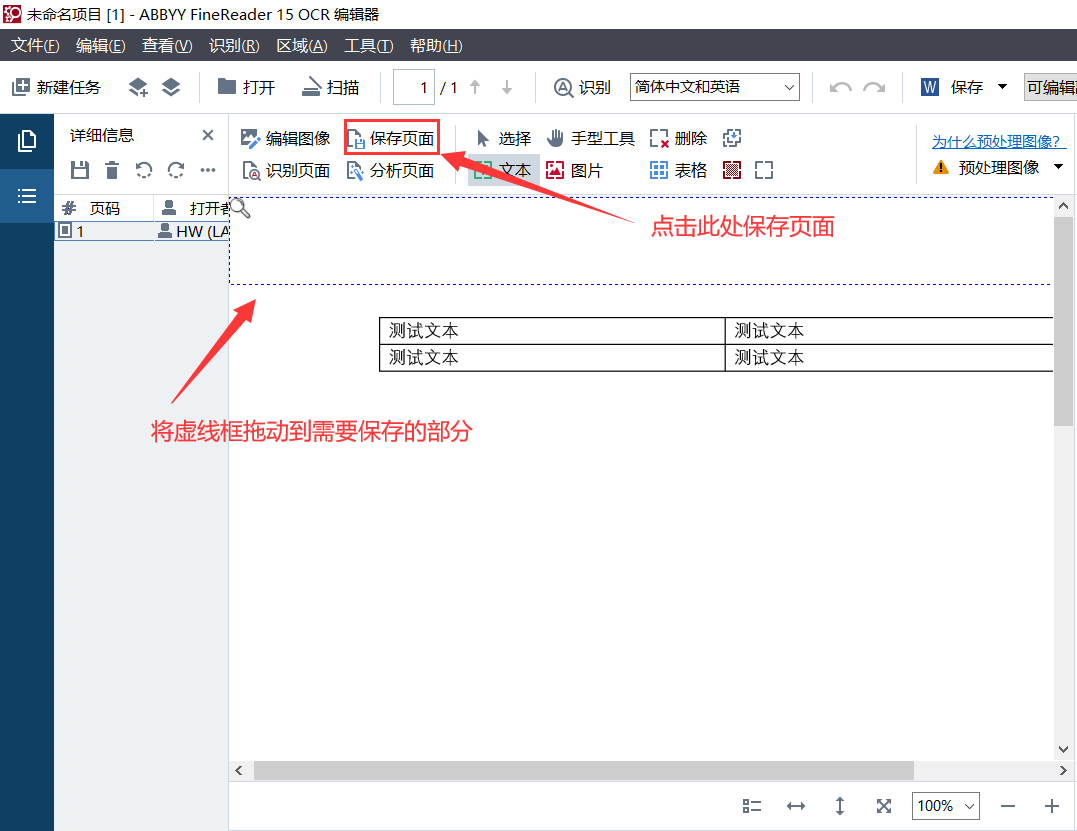
图四:示例图
在PDF文档中,除了表格不能直接保存,还有图片也是不能够进行直接保存的,如果我们想要在PDF文档中保存自己想要的图片,就必须在OCR编辑器中进行设置。
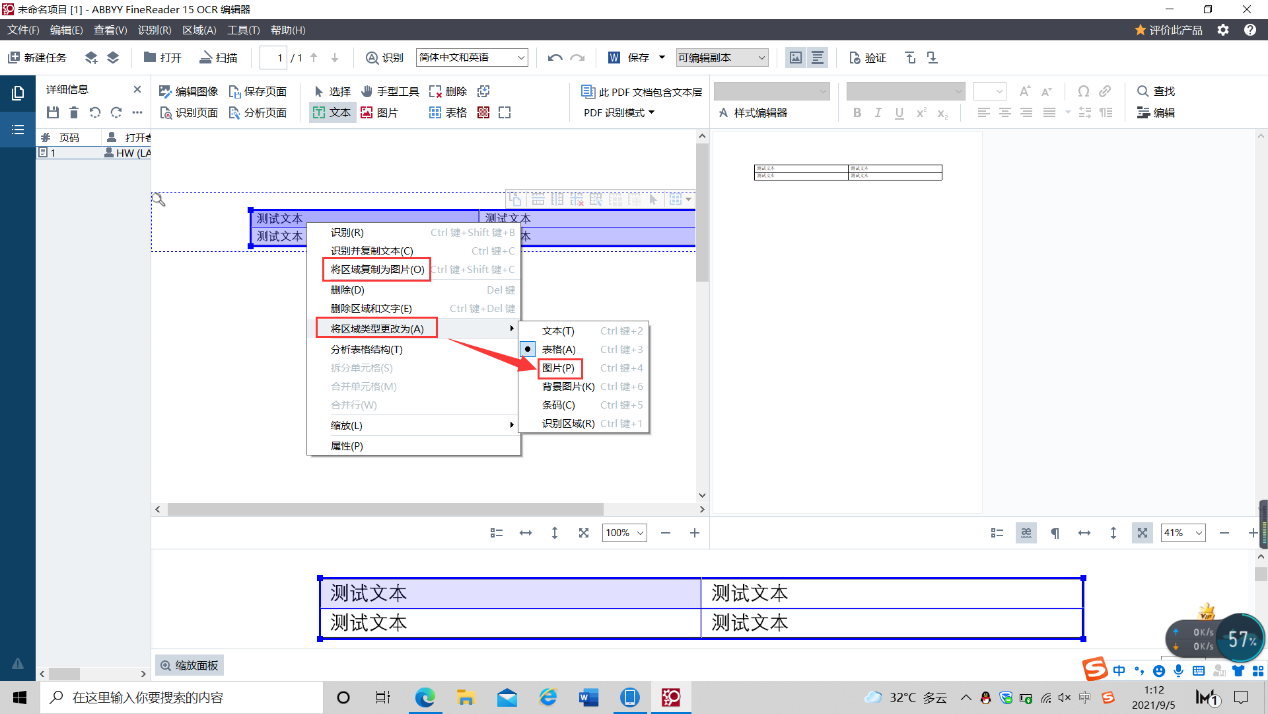
我们还是先将虚线方框拖动至我们想要保存的图片上,随后进行右键点击,如果我们保存的是单纯的图片形式的话,那么我们在对话框中直接选择“将此区域复制为图片”即可完成对图片的复制。
而如果我们需要将表格或者其他元素以图片形式保存下来的话,操作就会稍微繁琐一些,我们右键点击打开之后,选择“将此区域类型更改为”,随后在弹窗中选择“图片”,最后,我们再点击“将此区域复制为图片”选项即可完成操作。
好了,以上就是关于如何使用ABBYY Finereader 15保存PDF文档中的图片和表格的全部内容了,至于纯文本形式的PDF文档,我们用传统的方法也能够进行复制和粘贴,在这里就不过多赘述了。如果有对这款软件感兴趣的小伙伴们,欢迎前往ABBYY Finereader 15的中文网站上了解更多信息哦!
作者:LK
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

ABBYY如何批量转换PDF ABBYY怎么优化批量处理
在分享资料时,为了保护文件内容不被随意更改,我们通常会将Word文件转换为PDF格式,虽然这样能确保文件的安全性,但面对大量文件需要转换时,难免会让人感到困扰。在这里为大家推荐一款好用的转换软件——ABBYY FineReader,今天这篇文章就为大家分享一下ABBYY如何批量转换PDF, ABBYY怎么优化批量处理的相关内容。...
阅读全文 >

ABBYY怎么修改页面大小 ABBYY怎么修改PDF里面的文字
提到OCR文字识别软件,我们第一时间想到的就是ABBYY FineReader,它可以精确识别多种语言的文本,帮助用户快速转换不同格式的文件,今天我们就来带大家了解ABBYY FineReader的一些实用操作,看看ABBYY怎么修改页面大小,ABBYY怎么修改PDF里面的文字的具体步骤。...
阅读全文 >

PDF贝茨编号是什么 ABBYY怎么添加贝茨编号
使用PDF文件的人都知道,它有一个相关概念叫贝茨编号或者Bates编号、贝茨编码,贝茨码,这些概念说的是同一个意思。如果文字描述仍然让人觉得抽象,下面给大家介绍一下PDF贝茨编号是什么,ABBYY怎么添加贝茨编号的相关内容,学会这些让你更像成熟职场人。...
阅读全文 >

电脑文字识别软件哪个好用 电脑文字识别怎么操作
想把电脑中的图片、PDF资料整理为文字版,需要用到电脑文字识别软件,这样便于通过关键字检索资料提升工作效率。那么,电脑文字识别软件哪个好用,电脑文字识别怎么操作?下文整理了常用的几款软件,并且介绍了正确操作方法。...
阅读全文 >


