发布时间:2015-12-10 11: 38: 21
ABBYY FineReader 12作为市场领先的OCR光学字符识别软件,因其能够快速方便地将扫描纸质文档、PDF文件和数码相机的图像转换成可编辑、可搜索文本的功能,被越来越多的企业和个人广泛应用,作为当前版本,FineReader 12相比旧版本功能更强大,更全面,本文为大家整理了FineReader 12的完整功能(更多完整功能请参见ABBYY FineReader 12完整功能列表(二)、ABBYY FineReader 12完整功能列表(三)、ABBYY FineReader 12完整功能列表(四)),以列表的形式呈现给大家,方便大家更直观地了解学习这一软件。
无与伦比的OCR精确度
|
超常的识别精确度 |
支持高达99.8%的识别精确度 |
|
多语言文档识别 |
新增语言! 使用190种语言的任一组合处理文档;完整词典支持48种语言 |
|
自动识别文档语言 |
在一系列参数基础上自动选择文档语言 |
|
集成Microsoft Word自定义词典 |
允许创建自定义单词列表,用于处理行业特定文档 |
|
自定义用户词典 |
用户可以添加单词并创建自定义词典 |
|
保留字体和字体样式 |
已提高! |
|
智能背景过滤 |
在OCR识别之前采用动态阈值技术,将灰度和彩色图像转换为黑白图像,在实现更好的识别结果时自动调整对比度 |
|
处理非标准段落 |
支持识别垂直、彩色和反向文本 |
|
条码识别 |
支持识别1-D和2-D 条码 |
精确的布局和格式保留
|
文档布局保留 |
改善表格和图表! FineReader保存多页文档的结构,并且保留几乎所有文档布局元素:目录、页眉和页脚、图表、图表、文本行、图像、表格等 |
|
表格结构重建 |
已提高! 能够准确识别和重建表格及电子表格,包括多页表格,在Microsoft Word或Excel中完全可编辑 |
|
表格单元格内容识别 |
允许指定单元格类型和属性,比如FineReader图像窗口中的文本方向、图像、语言和数字 |
|
使用图像标头将表格保存为Excel |
新增!保存为Excel时保留图像 |
|
多表格文档转换 |
新增!将每个页面从原文档转换为Microsoft Excel中单独的表格 |
|
重建要点和编号 |
将要点和编号转换为本地Microsoft Word列表 |
|
准确识别杂志形式页面 |
使用集成文本提供自动和准确的复杂页面图像转换,用户可以手动标记文本区域,以便使用背景图像有效处理文档 |
|
保留超链接 |
支持检测超链接并将其转换为真正的超链接 |
|
处理协议类型文档 |
能够识别包含签名或公章的文档 |
|
处理行编号 |
可以从各种类型的法律文档中删除行编号 |
更多关于ABBYY FineReader 12新特性的内容,请点击参考ABBYY FineReader 12有什么新特性?。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:
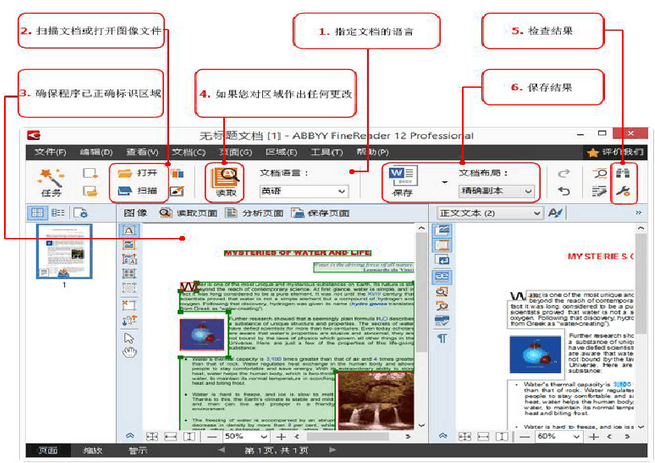
怎么用ABBYY识别表格 ABBYY表格数据怎么提取
经常和各类文档打交道的用户应该都熟悉ABBYY FineReader。和只能提取纯文本的其他OCR工具不同,ABBYY FineReader能全面解析识别复杂文档结构,包括但不限于表格数据、手写内容、图片,还能保留文档的原始结构。为了让大家更好地掌握ABBYY FineReader的强大功能,本文将围绕怎么用ABBYY识别表格,ABBYY表格数据怎么提取的详细操作方法展开介绍。...
阅读全文 >
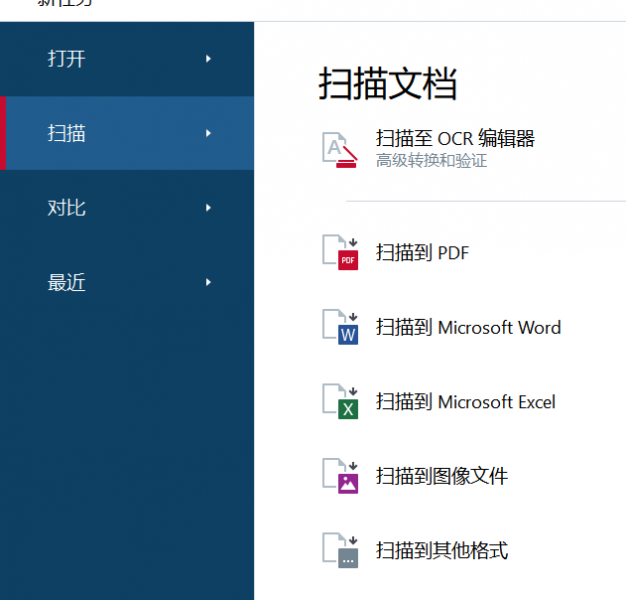
怎么用ABBYY扫描文档 ABBYY怎么保存扫描记录
对于许多办公党和学生党来说,利用扫描工具把纸质文件扫描成电子文件并进行整理是一项常见的需求,而在ABBYY FineReader软件中,就可以方便地实现这一功能。接下来我们就一起来了解下怎么用ABBYY扫描文档,ABBYY怎么保存扫描记录的具体操作。...
阅读全文 >

PDF文字怎么编辑修改 PDF文字怎么复制
在日常工作学习中,如果遇到需要修改PDF文字内容的情况,可能很多小伙伴首先考虑的是先将PDF文件转换成word后再进行修改,但这种方式极大降低了我们的工作效率。其实,直接使用ABBYY FineReader PDF软件就可以轻松帮助我们解决PDF编辑的困扰。接下来,本篇文章将带大家了解一下PDF文字怎么编辑修改,PDF文字怎么复制的相关内容,希望对大家有帮助。...
阅读全文 >

如何把PDF合并到一起 多份PDF如何拼接成一份
在进行PDF文件编辑操作时,为了有效简化文档管理,提高工作效率,我们往往会将多个pdf合并成一个,但还有部分小伙伴不知道如何把pdf进行合并操作,今天这篇文章将带大家了解一下如何把PDF合并到一起,多份PDF如何拼接成一份的合并方法,简单几步就能完成,一起来学习下吧。...
阅读全文 >


