发布时间:2015-12-29 17: 28: 54
缅甸联邦共和国,原名缅甸,是东南亚的一个国家,从1962年到2010年,缅甸一直被政变后上台的军政府统治,直至最近5年它才对外界开放,与其他国家建立了贸易与文化联系。
缅甸语由很多方言组成,但所有方言都共享一个核心字母表,该核心字母表主要用于正式文本和印刷媒体,有33个辅音和12个辅助字符,地区方言可能还使用其他字符,完整列表大约有核心字母表的三倍大。幸运的是,我们的工作是识别使用流行的至少10点大小的缅甸3字体书写的标准缅甸文本,文本图像可以是灰度、黑白或彩色的,分辨率至少有300dpi,下面是典型的缅甸文本样板:

在项目初步阶段,我们必须实现75%的OCR准确度,较小目标准确度为94%。
缅甸脚本就是所谓的alphasyllabary,在这里每一个辅音字母也都传达“默认”元音声,其他元音声使用特殊字符和辅音上面、下面、前面、后面的变音符号甚至辅音周围的变音符号转录。
字母大多由半圆组成,因为在过去,文本都是写在棕榈叶上,很容易被直线切口损坏。
缅甸语是一种有声调的语言,有三个主要声调—高、低和嘎吱声,和两个次要声调—入耳调和降调。
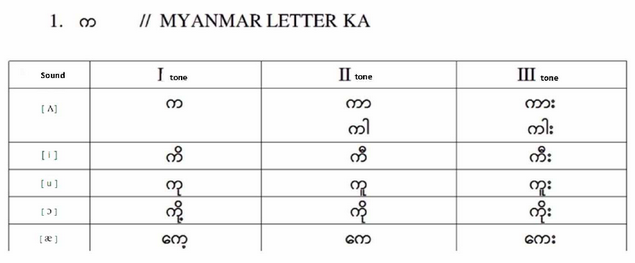
由于声调也要在书写中进行转录,缅甸脚本实际上有两种可分辨的符号,可能放在主要字母上面、下面或同时放在主要字母的上面和下面,这两种层叠的可分辨系统给OCR软件带来了重大挑战,但不仅仅如此。
若要让事情变得更复杂,有些字母组合可以融合在一起形成新字符。
在大多数常规术语中,光学字符识别如雷贯耳。当OCR软件收到图像文件时,它会使用OCR技术执行一些初步处理,将图像转换为黑白文本并纠正看得见的扭曲,接下来检测包含不同类型文本(标题、正文、脚注)、照片和表格的区域,文本块随后解析成行,行再到单词,单词再到字母,单个字母识别完成之后,文本将自下至上重组,缅甸文本的图像处理和板块检测和大多数其他语言里的操作一样,但是检测文本行是一件棘手的事。
由于变音符号的丰富性,教电脑识别短文本行非常困难,这就是原因所在,我们的运算法则使用很多功能体现文本行,其中的一个功能是虚构的基线,所有主要字符都位于这个基线上,电脑需知道在哪里画一条基线,以便生成有关单个字符的合理假设。
电脑使用统计数据检测基本文本行,为了收集必要的数据,要观察构成字母的黑点生成的直方图上的峰值,在欧洲字母的直方图上,有三个清晰可见的峰值对应于基线和小写字母的高度:

然而在缅甸语中,文本行正常宽度以外的众多变音符号在直方图中导致额外的统计学上有意义的峰值,为此,我们的最初面向欧洲脚本的运算法则,无法正确地识别缅甸文本行的重要参数。
在下面的图形中,程序正确地检测到了前两行,但没有检测到第三行:

针对文本行检测运算法则,我们必须要做一些调整,让其同样适用于缅甸文本。
本文中我们提到的OCR技术指的就是ABBYY FineReader 12,更多相关内容,请点击进入ABBYY中文服务中心,查找您需要的信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:
PDF转成图片的方法 PDF转图片不清晰怎么办
PDF文档和图片都是常用的文件格式,在工作中我们需要根据不同的需求来灵活地对文件的格式进行更改,这就需要我们掌握PDF转成图片的方法。PDF转图片不清晰怎么办?下文中会为大家进行详细地解答。...
阅读全文 >
PDF如何转换Word文档 PDF转word格式乱了怎么调整
对于一些经常需要处理文档的工作者来说,文档的格式转换是十分常见的。然而我们在将PDF文件转换成Word文档时会出现格式乱了的情况,那么我们接下来就来说一说PDF如何转换Word文档,PDF转Word格式乱了怎么调整。...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 