发布时间:2021-11-05 11: 13: 05
ABBYY FineReader PDF 15常常作为一款优秀的OCR文字识别软件被大家所熟知,其强大的OCR扫描功能能够精准识别文字并转化成可编辑可搜索文档,给我们的日常生活带来极大的便利。在使用ABBYY FineReader PDF 15的OCR扫描功能时,我们也必须要注意OCR识别语言的选择是否和图像扫描内容相匹配,如果语言设置不正确会导致OCR识别不出正确的文本内容。接下来,我就为大家讲解一下ABBYY的OCR识别语言设置教程。
第一、运行OCR编辑器
ABBYYFineReaderPDF15默认的OCR识别语言为简体中文和英语,如果我们要扫描的图像文本内容为日文,那么扫描出来的结果就会如图1所示为乱码。
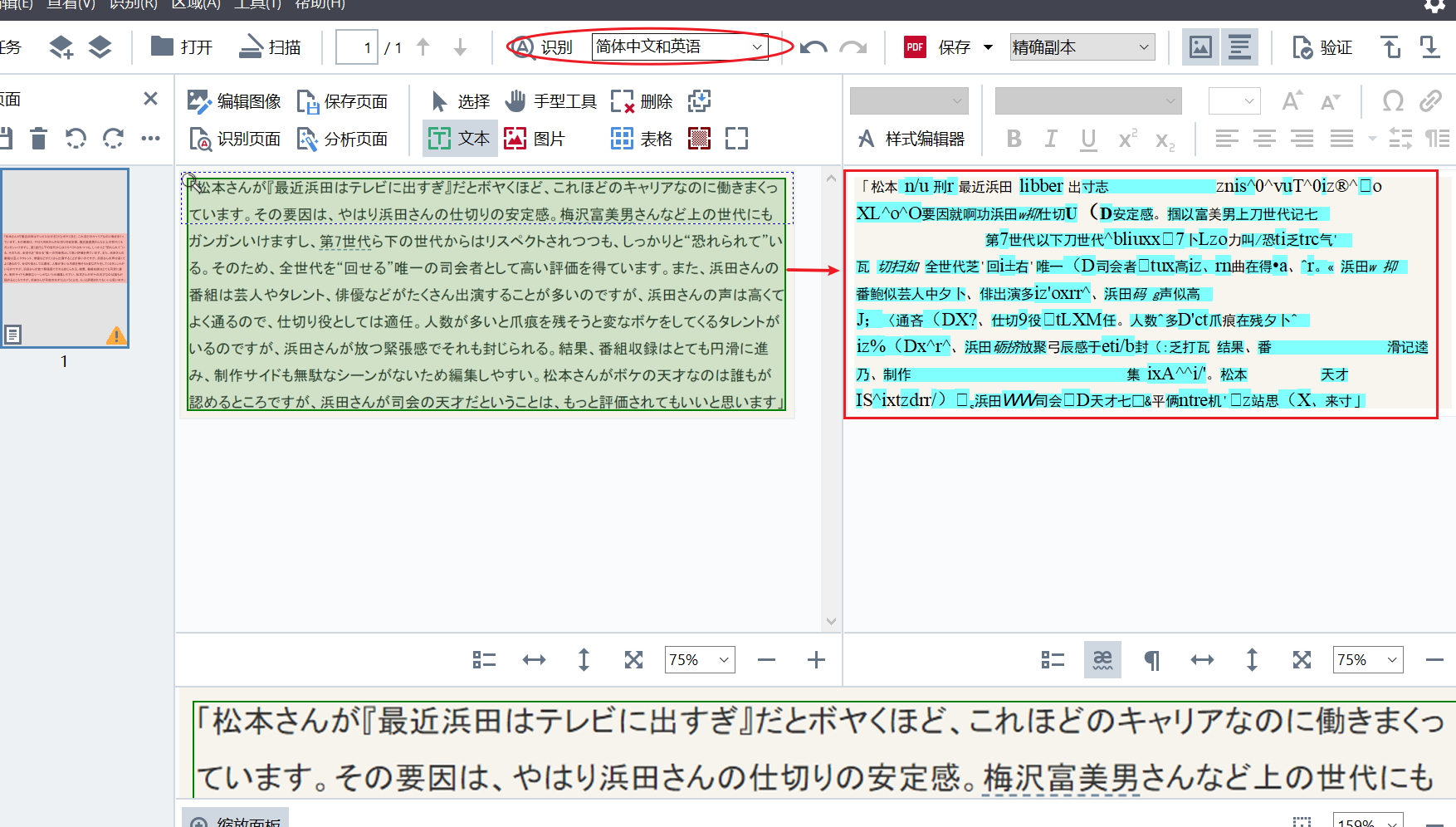
第二、设置OCR识别语言
打开OCR编辑器上方识别语言隐藏菜单,查看菜单栏内是否存在和扫描内容相匹配的语言。如果没有,点击底部“更多语言”选项,进一步查找匹配语言。
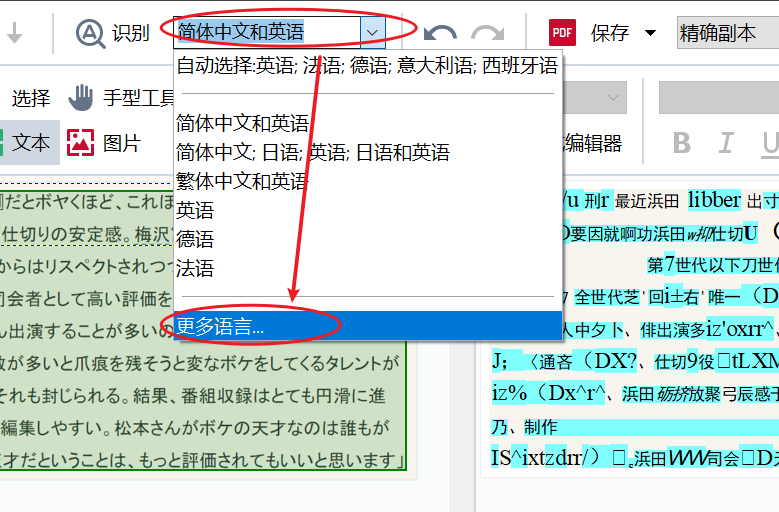
第三、手动指定OCR识别语言
进入OCR的语言编辑器界面后,在手动指定OCR语言栏内找到并勾选对应的语言,接着点击右下角的“确定”选项。
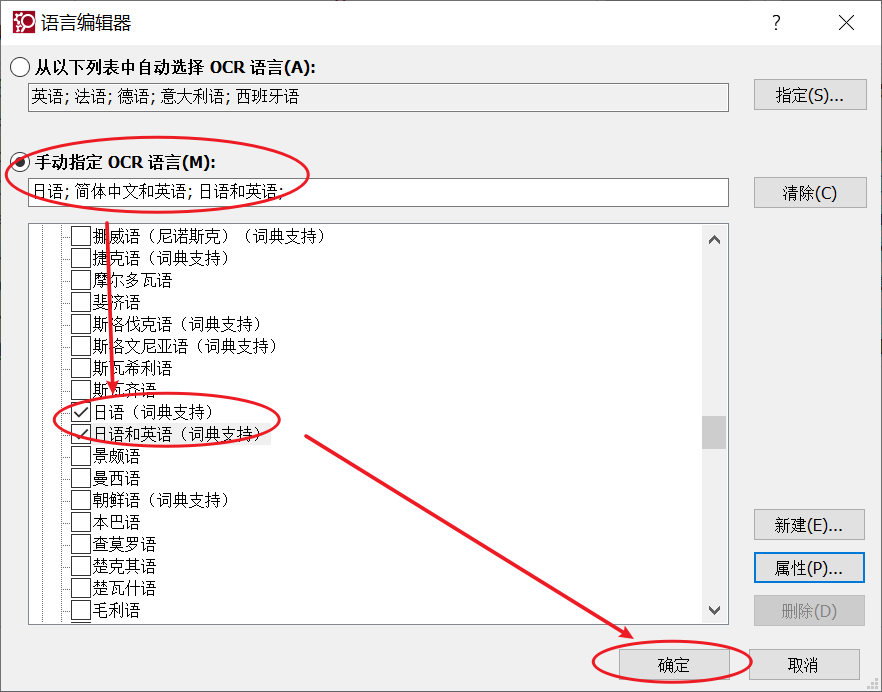
第四、重新扫描识别导入图像的文本内容
OCR语言重新设置之后,回到OCR编辑器主界面,点击“识别”选项对导入图像进行OCR扫描转化操作。如图4所示,此时转化后的文本与左侧图像对比精确度极高,如果检查后出现识别偏差,我们可以直接在右侧转化文本上进行修改。
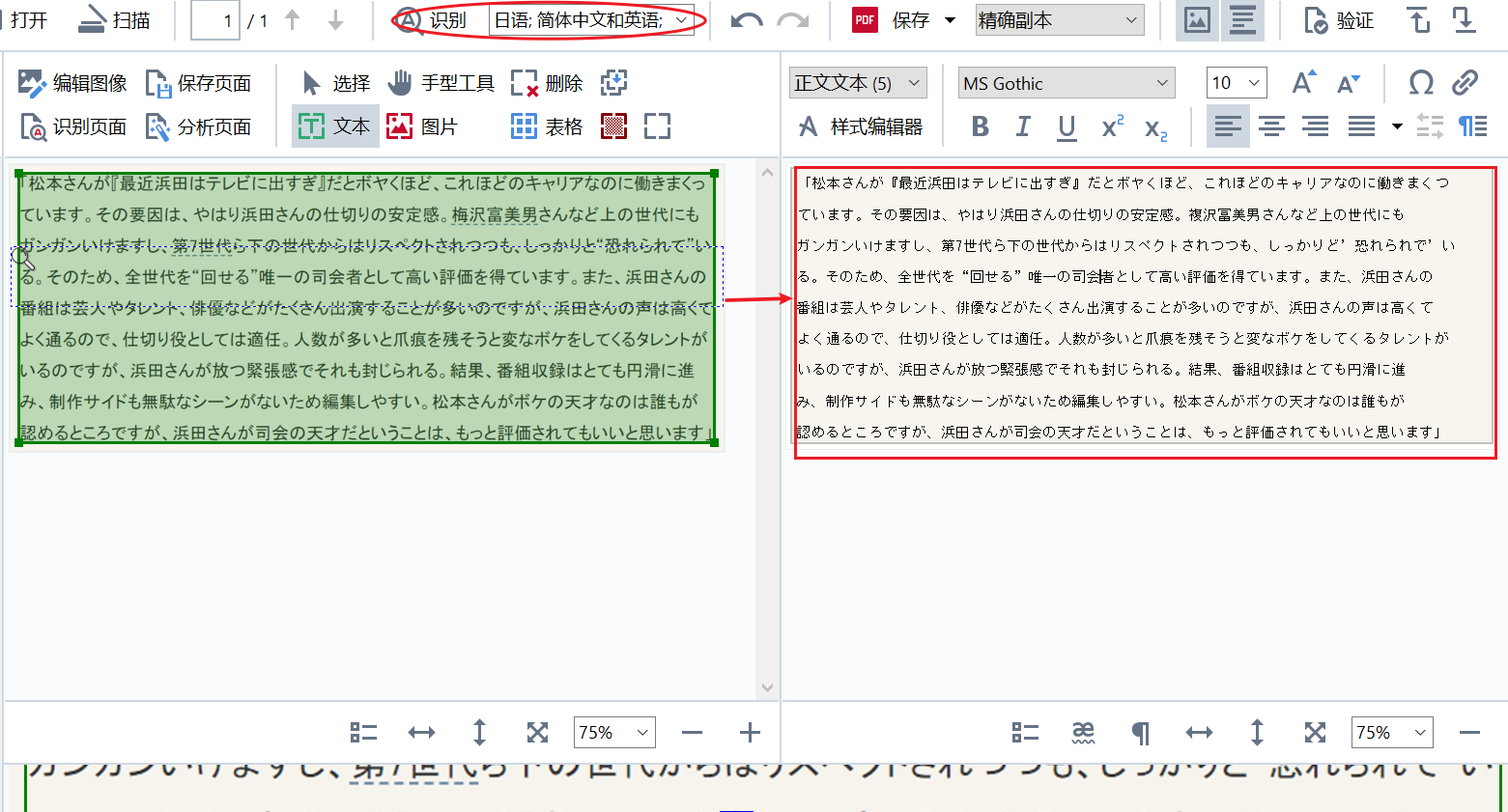
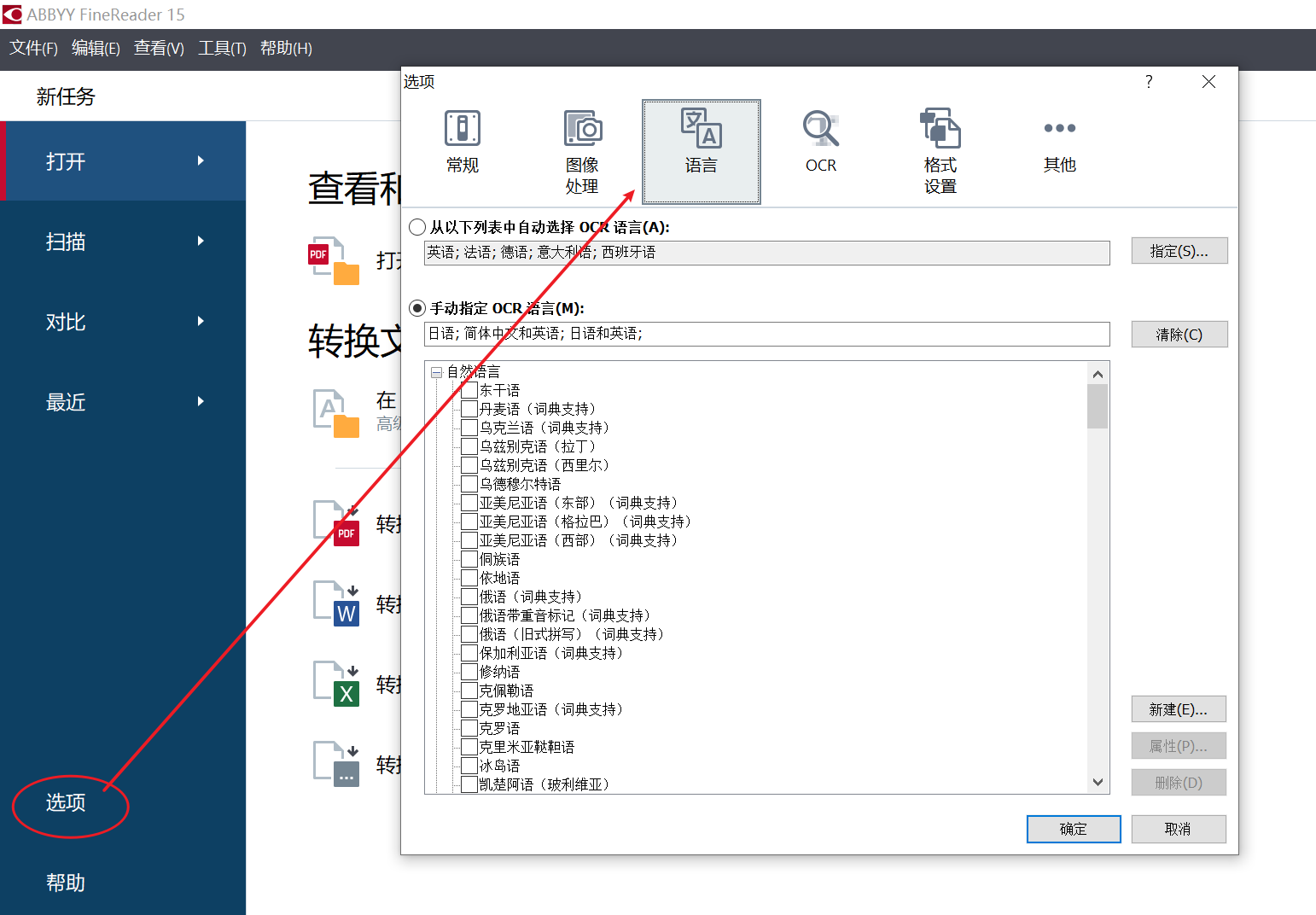
此外,我们还可以点击ABBYYFineReaderPDF15主界面左下角的“选项”设置,在弹出的设置界面中找到语言设置界面,在语言设置界面中重设OCR的识别语言。
以上就是ABBYY的OCR识别语言设置教程的具体操作步骤,只有将OCR识别语言设置成合适的语言模式,我们才能得以顺利高效地完成OCR扫描转化操作。ABBYY FineReader PDF 15软件除了OCR扫描这一优势之外,还可以作为PDF编辑器对PDF文档进行编辑和处理,如果大家感兴趣的话请访问ABBYY FineReader PDF 15中文网站。
作者:Blur
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

如何用ABBYY处理倾斜文字 怎么用ABBYY批量处理文字
经常使用ABBYY FineReader处理扫描文档的小伙伴应该都知道,掌握软件的操作技巧能省去不少麻烦,但在实际应用中,如果遇到页面倾斜导致文字识别不准,或大量文件需要处理的情况,效率很容易受到影响,甚至可能耽误工作进度。别担心,接下来就带各位了解如何用ABBYY处理倾斜文字,怎么用ABBYY批量处理文字的相关内容。...
阅读全文 >
怎么用ABBYY扫描文档 ABBYY怎么保存扫描记录
对于许多办公党和学生党来说,利用扫描工具把纸质文件扫描成电子文件并进行整理是一项常见的需求,而在ABBYY FineReader软件中,就可以方便地实现这一功能。接下来我们就一起来了解下怎么用ABBYY扫描文档,ABBYY怎么保存扫描记录的具体操作。...
阅读全文 >

ABBYY怎么把图片添加到文档中 ABBYY怎么把图片转换成Word
ABBYY FineReader是一款集OCR和PDF功能于一体的专业文档处理软件,支持将纸质文档和扫描件转换为可编辑的电子文档,还能完成各种不同格式的文件转换。接下来我们就来带大家了解一下ABBYY怎么把图片添加到文档中,ABBYY怎么把图片转换成Word的相关内容,帮助大家轻松处理办公需求。...
阅读全文 >

ABBYY怎么拆分PDF ABBYY怎么编辑PDF
在处理研究报告时,将冗长的PDF文档拆分成多个小文件,可以便于研究和查阅,提升我们的阅读体验,但很多用户不知道该如何对PDF文档进行拆分,今天我们就通过ABBYY FineReader,为大家演示ABBYY怎么拆分PDF,ABBYY怎么编辑PDF的相关技巧,赶紧接着往下看吧!...
阅读全文 >


