发布时间:2016-06-03 16: 29: 23
你曾遇到过PDF难题吗?比如,无法选择文本进行复制,或者搜索PDF文档中已有的单词时,却搜索不到任何结果,原因很简单,只要有正确的工具,问题就能轻松解决。
PDF文档根据文件创建的方式,可分为三种不同的类型,文件最初的创建方式规定了PDF内容(文本、图像、表格)能否访问,或是否“锁定”在页面图像中。
想要理解PDF的结构,应该按照图层来理解。上面一层只是一张图片,如果你想访问文本,则需要有第二图层,即文本层,位于图片层下面,被隐藏了。
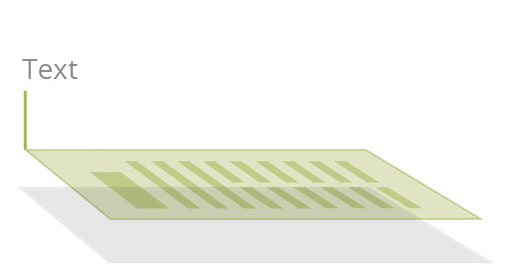
使用软件Microsoft Word、Excel,或者通过软件应用程序(虚拟打印机)中的“打印”功能创建,由文本和图像组成。可搜索,内容可访问,以便注释和重复使用。
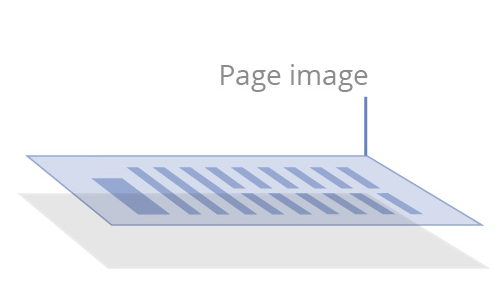
由一体化设备和办公室扫描仪上的扫描纸质文档创建,或者转换jpg或tiff图像为PDF时创建。
仅包含扫描的或者拍摄的页面图像,底下不带有文本层,内容“锁定”在快照图像中。不可进行搜索,内容不可访问。
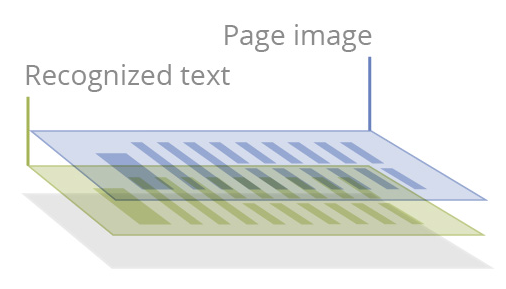
文本层被添加到图像层,通常放在下面,可进行搜索,内容可访问,可进行注释和重复使用。可能会出现一些限制,比如图片元素和图像。
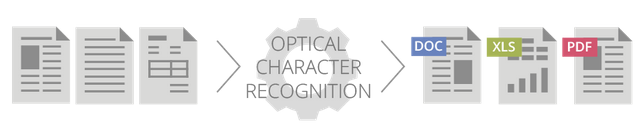
很多扫描仪都可以创建PDF文档,但也仅限于创建图像或文档快照,不过就是一堆黑白或彩色的点,称为光栅图像,无其他数据。要想从扫描文档或“仅图像”PDF文档中提取并利用数据,需要OCR文字识别软件,比如ABBYY FineReader,或者PDF工具,如ABBYY PDF Transformer+。
光学字符识别或者文本识别可以解锁“困”在扫描/拍摄的文档图像上的信息,OCR软件可以通过翻译字符图像“读取”文档里的内容,让转换文档内容和布局为可搜索和可编辑的格式成为可能。
现在你知道了:每次想要选取PDF文档里的内容时都会失败,要么就是无法搜索文档里的关键词,几乎就是在处理扫描的“仅图像”PDF文档。
有了OCR,使用ABBYY FineReader,就可以将扫描的“仅图像”PDF文档转换为包含可选择和可搜索文本的PDF文档,实现轻松管理、复制和索引内容,以及全文本搜索。
•可以处理扫描的纸质文档和“仅图像”PDF文档,就跟处理数字创建的PDF文档一样;
•可以更加快速地从文档中找到并访问信息,再也不用在纸堆里翻箱倒海了;
•可以重复使用文档里的信息,无需手动重新输入;
•和同时协作的时候,可以选择文本进行强调、评论和添加注释;
•可以使用“搜索和编辑”功能编辑文档中出现的机密信息。
更多关于ABBYY FineReader和ABBYY PDF Transformer+的信息,点击访问ABBYY中文网站进行了解吧。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >
图片扫描文字识别软件有哪些 图片扫描文字识别怎么弄PDF
在工作中,有时我们需要将图片中文字摘录下来。为了快速完成工作,我们会使用图片扫描文字识别软件。今天小编就给大家介绍一下,图片扫描文字识别软件有哪些,图片扫描文字识别怎么弄PDF。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >
照片文字转成文档的软件有哪些 怎么把照片上的文字转成文档
日常办公中,会遇到将图片上的大段文字转化成文本的情况,难道只能一个个用键盘输入?有没有更加便捷的方法?今天就带大家解决:照片文字转成文档的软件有哪些,怎么把照片上的文字转成文档呢?...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 