发布时间:2017-02-16 11: 36: 06
ABBYY Recognition Server作为一种功能强大的自动识别系统,可以自动转换纸质文档、图像和电子文档,并将它们保存为压缩的归档文件,如PDF或PDF/A。ABBYY Recognition Server的自动化文档处理过程包括六个阶段,这些阶段可以在单独的工作流程中进行配置,每个工作流有其特定的设置和优先级,且彼此独立运行,本文将具体讲讲ABBYY Recognition Server自动化处理文档的流程。

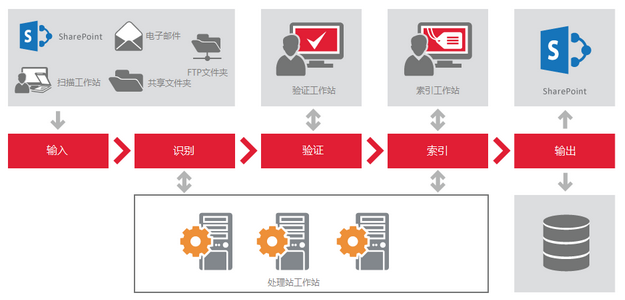
图像可以由操作者在扫描站扫描后发送到Recognition Server或者通过Recognition Server从输入文件夹(网络文件夹、FTP文件夹、SharePoint库或邮箱)自动导入,该应用程序根据优先级和可用计算资源自动处理在队列中的图像文件。
作为批次扫描的图片, ABBYY Recognition Server提供几种内置文档分割方式可选:空白页、条码或者页面上的粘贴以及打印条码,同时还支持脚本方式书写以外的客户规则。
ABBYY Recognition Server的OCR识别是在处理站自动运行的。如果同时安装多个处理站在系统中,这些文件将这些处理站之间均匀分布,以获得高性能,安装多个处理站能够加快OCR识别速度。
ABBYY Recognition Server的OCR和条码识别技术提供了无与伦比的精确性,支持多种类型文本,以及流行的1D/2D条码。Recognition Server支持198多种语言,包括拉丁文、西里尔文、希腊和其他脚本,中文、日语、韩语、越南语、希伯来语、意第绪语和泰国等,欧洲的古体语言也支持。
为保留文档版面, ABBYY Recognition Server使用Adaptive Document Recognition Technology (ADRT)技术,在保存成DOC和RTF时很好地保留文档的原始版面,包括页眉、页脚、表格内容等。
在某些情况下,例如书籍数字化时,验证识别结果可能是必要的。验证站能够让操作者检查所有的文件或者只检查低于一定精确度的文件。
执行批量扫描或导入的时候,将涉及到文件分离。文件可以用空白分隔页,条形码或每个文档页面固定数目分开的,分离也可以根据脚本规则进行。
ABBYY Recognition Server是一个强大的索引软件。文件索引可以通过脚本自动完成或者由操作员在索引站手动选择文件类型并指定文件属性,操作员也可以检验由脚本自动导出的数据。文档类型的探测、分类和索引可以通过Java或者VB自动实现。
文件处理的最后阶段,ABBYY Recognition Server将文件输出到其最终储存处(网络文件夹、SharePoint文件库或电子邮件)。此外,输出的文件还可以应用于智能路由或发送至基于文档属性和特性的ECM系统。
识别服务器可以将图片转换成不同的可搜索的文件格式:PDF、PDF/A、RTF、TXT、DOC(X)、XLS(X)、XML。
更多有关ABBYY Recognition Server的内容,请点击访问ABBYY教程了解更多。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

pdf编辑器怎么删除页码 pdf编辑器怎么删除部分内容
PDF编辑器是一种用于编辑PDF文档的软件工具,用户可以在其中对PDF文档进行各种操作,比如修改、添加、删除文本和图像,以及调整页面布局、插入注释和标记等。页码是文档页面的编号,通常显示在每页的底部或顶部。...
阅读全文 >

ABBYY是免费的吗 ABBYY正版软件多少钱
在我们日常工作中,你是不是也经常遇到一些文字识别方面的问题,如果我们按照传统的方式,逐字逐句地手动输入将图文转化为文本,会浪费很多时间。所以,今天小编给大家推荐一款OCR文字识别软件,它就是ABBYY FineReader PDF 15。它可以自动扫描并提取图片上的文字内容,方便我们复制粘贴以及编辑。下面就讲讲大家关心的问题ABBYY是免费的吗,ABBYY正版软件多少钱。...
阅读全文 >

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 