发布时间:2015-08-31 15: 27: 07
ABBYY PDF Transformer+可让您从不包含文本层的PDF文档中搜索或复制文本和图片,如扫描文档和从图像文件创建的文档。这可能归功于后台运行的识别过程。本文就讲述了ABBYY PDF Transformer+的后台识别过程。
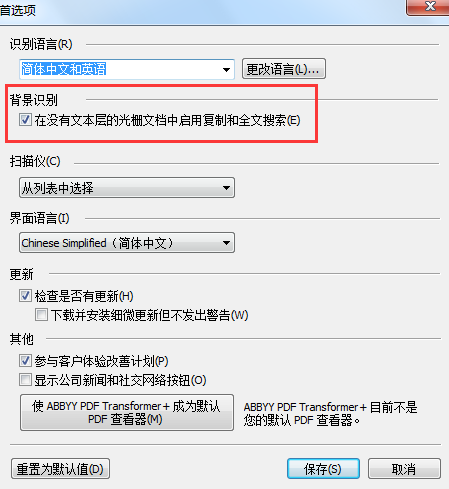
后台识别在默认情况下运行即启用。当您打开无文本层的 PDF 文档时,它自动启动。
但是这里要知道的是,后台识别过程无法在单核处理器的计算机上运行。
后台识别过程不会改变 PDF 文档的类型,因此,如果您保存了仅图像文档并使用另一应用程序将其打开,您将无法再搜索它或复制其内容。
要使 PDF 文档可搜索,您需要对其添加文本层。
如果搜索或复制功能不能正常运行,请查看是否已正确指定文档语言。参见ABBYY PDF Transformer+改善转换结果之识别语言以获取更多信息。
您可通过在首项对话框中清除在没有文本层的光栅文档中启用复制和全文搜索复选框,随时禁用后台识别过程。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >
ABBYY FineReader 12激活教程
安装完 ABBYY FineReader 12 之后,需要激活程序才能在完整模式下运行。在受限模式下,将根据您的版本和所在地区禁用一些功能。...
阅读全文 >

ABBYY FineReader 12注册码-激活码-序列号地址
ABBYY FineReader 12 OCR图文识别软件自2014年4月发布以来,屡获殊荣,是图像和文件识别以及办公的好帮手,那么对于这样一款用途广泛的软件来说,如何获取注册码、激活码或序列号想必是大家最关心的问题。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 