发布时间:2016-07-25 15: 57: 46
ABBYY FineReader Pro for MacOCR文字识别软件处理文档的步骤主要包括以下四步:检索文档图像、分析文档结构、识别文档和将文档导出至FineReader支持的应用程序或格式。可以使用快速任务转换文档,使用此种方法转换文档时,只需单击一下鼠标。如果文档是复杂的多页文档,可以进行手动处理,以便获取合适结果并自定义输出,本文具体讲讲FineReader处理文档的主要步骤。
将文档图像转换成可编辑的格式时,需要执行以下四个步骤:
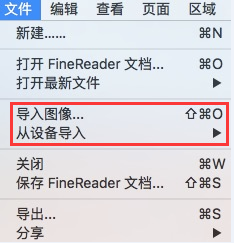
在处理文档之前,必须先将其页面图像导入到程序中。
•若要扫描纸质文档,请选择文件 > 从设备导入。
•若要从移动设备导入图像,请选择文件 > 从设备导入。
•若要从文件系统导入图像文件,请选择文件 > 导入图像。
导入图像之后,软件将会自动分析原始文档的结构和格式,将会检测图像中的文本、表格、图像和条码区域。
如果文档结构非常复杂,或者已禁用“自动页面分析”功能,可能需要手动调整已检测的区域。
务必为文档选择正确的文档语言。
默认情况下,软件会在分析完文档结构之后自动开始识别。如果已禁用自动识别功能,或者调整了已检测区域,或者更改了文档语言,请单击工具栏中的“读取”按钮。

若要导出识别结果:
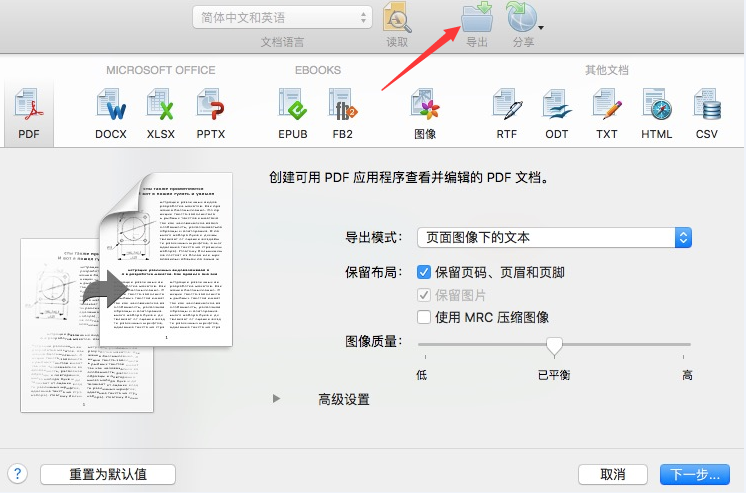
1、单击工具栏中的“导出”按钮,或者选择文件 > 导出。
2、单击所需的输出格式,并自定义导出参数。
3、单击“下一步”,前往“保存”对话框。输入文档名称、文件保存位置,并选择所需的文件保存选项。
提示:如果希望在导出文档后立即处理已转换的文档,请选中“导出”对话框中的“保存后打开文档”。
更多关于ABBYY FineReader的使用问题,请点击访问ABBYY中文教程中心,查找更多内容。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:
PDF转成图片的方法 PDF转图片不清晰怎么办
PDF文档和图片都是常用的文件格式,在工作中我们需要根据不同的需求来灵活地对文件的格式进行更改,这就需要我们掌握PDF转成图片的方法。PDF转图片不清晰怎么办?下文中会为大家进行详细地解答。...
阅读全文 >
ABBYY FineReader PDF 安装、激活、换机教程
ABBYY FineReader PDF 是一款专业的OCR文字识别软件,ABBYY基于AI的OCR技术,在现代工作环境中使各种文档的数字化、检索、编辑、保护、共享和协作变得更容易。减少了由多种原因导致的效率低下,不可访问、不可查找的文档和信息;涉及纸面文档和数字文档混合的工作流;以及需要使用多个软件应用程序的任务。那么当你购买了ABBYY FineReader PDF之后,当想需要换电脑的时候,怎么才能完成ABBYY安装、激活、换机操作呢,下面本篇文章就来为大家解答一下相关步骤。...
阅读全文 >
excel转换word后如何排版 excel转换word后怎么调整页面
很多时候我们需要将excel转换为word文档,那么excel转换word后如何排版,excel转换word后怎么调整页面,相信许多朋友对这两个问题很感兴趣,下面就由我来为大家详细讲解一下吧。...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 