发布时间:2017-05-15 15: 34: 42
在使用ABBYY FineReader 14OCR文字识别识别文档时,要想获得快速准确的结果,选择正确的OCR选项很重要,决定好要使用的选项之后,还应该考虑文档的类型和复杂性,以及如何去使用识别结果。
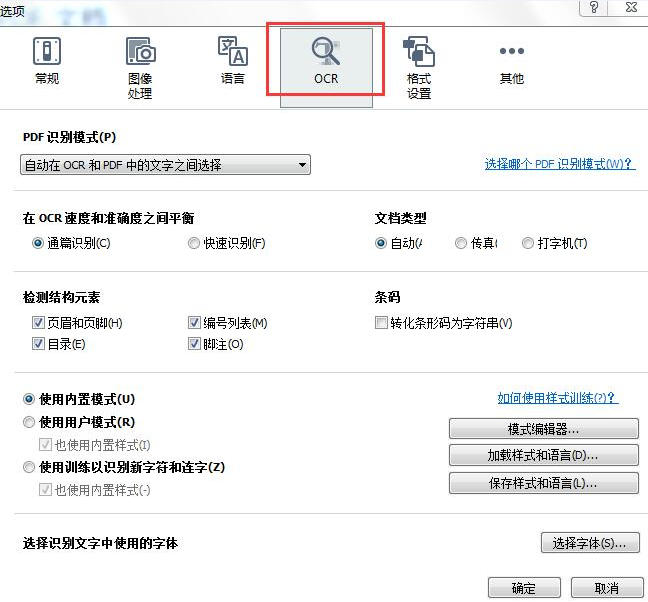
OCR选项位于ABBYY FineReader‘选项’对话框的OCR选项卡上(点击工具 > 选项…打开此对话框)。
ABBYY FineReader 14可以自动识别添加到OCR项目的任何页面,当前选定的选项将用于OCR过程,你也可以在图像处理选项卡上关闭新添加的图像的自动分析和OCR。
注意:如果在文档识别之后修改OCR选项,需再次运行OCR过程,通过新选项识别文档。
这些设置仅适用带有文本层和图片的PDF文档,这种PDF文档通常从可编辑格式的文档创建,其他类型的PDF文档,比如可搜索的PDF文档和仅图像PDF文档,通常在‘使用OCR’模式中处理,处理这种类型的PDF文档无需额外的设置。
有三种识别模式可以使用:
程序会检测文本层,如果它包含高质量的文本,便使用现有的高质量文本层,OCR将用于创建新的文本层。
OCR将用于创建新的文本层,这种模式花费的时间更多,但更适用于文本层质量较差的文档。
这是带有文本层PDF文档的默认模式,程序会使用原始文本层,无需运行OCR。
ABBYY FineReader 14可以让你:
在这种模式下,FineReader 14既可以分析和识别简单的文档,也可以分析识别布局复杂的文档。这种识别需要更多时间,但最终的效果也更好。
这种模式建议用于处理布局简单且图像质量较好的较大文档。
选择你希望程序检测的结构元素:页眉和页脚、脚注、目录以及编号列表,保存文档之后,选中的元素将可点击。
如果你的文档包含条码,你希望将它们转化为字符串和数字,而不是保存为图片,则勾选‘转化条形码为字符串’,该功能通常是默认禁用的。
有关ABBYY FineReader 14的更多内容,请点击访问ABBYY教程了解更多信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:
PDF转成图片的方法 PDF转图片不清晰怎么办
PDF文档和图片都是常用的文件格式,在工作中我们需要根据不同的需求来灵活地对文件的格式进行更改,这就需要我们掌握PDF转成图片的方法。PDF转图片不清晰怎么办?下文中会为大家进行详细地解答。...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >

Word图片转文字在哪 Word图片转文字怎么转换
有时候我们需要把图片中的文字提取出来进行编辑,所以需要将图片转为Word文字,那么如何将图片转文字呢?下面就为大家讲解一下Word图片转文字在哪,Word图片转文字怎么转换。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 