发布时间:2016-03-11 11: 20: 28
随着OCR文字识别概念的深入人心,人们越来越依赖有效的工具,推动日常工作的进行,想要效率比别人高,选择合适有用的软件至关重要,你看列夫•托尔斯泰的90卷著作,如果没有ABBYY FineReader OCR图文识别技术的帮助,也不可能在短短2周时间里完成数字化处理,继而上传到网络供公众阅读。
对于这样一款高效工具,小编为大家介绍过不少使用技巧和应用,但实际操作过程中难免会遇到一些问题,特别在识别文件方面,接下来我们就一起总结下使用过程中可能会出现哪些问题,以及如何处理这些问题。
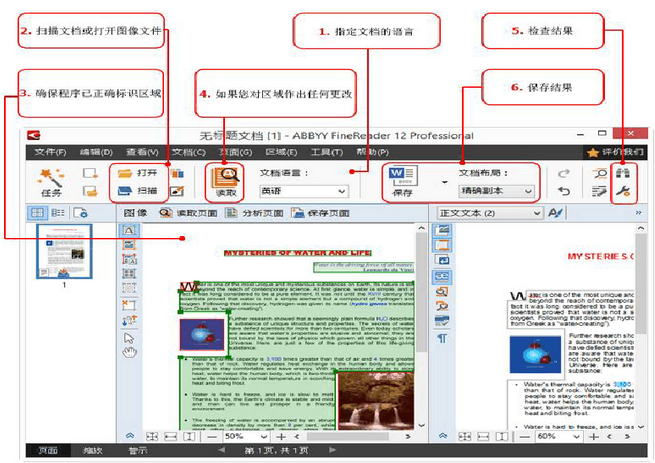
在识别文件过程中,如果图像质量不太好,应该怎么做呢?可以直接在FineReader中通过多种方式提高图像质量,如果某些因素无法改进,应重新获取没有缺陷的图像。图像满足以下条件就可以提高识别效果:
•扫描后图像没有任何几何失真,厚书靠近书脊部位没有变形或明显弯曲;
•给文件拍照后,除满足上述条件外,文档没有任何非线性几何失真(如梯形),整个区域聚焦均匀(亮度同样要均匀),没有光线不足导致的任何噪声,没有明显的光点(特别是光面纸)。
用户可以选择文档语言、图像预处理方案、某些分析和识别属性,也能进行这些设置,下面是其中一个属性选项截图:
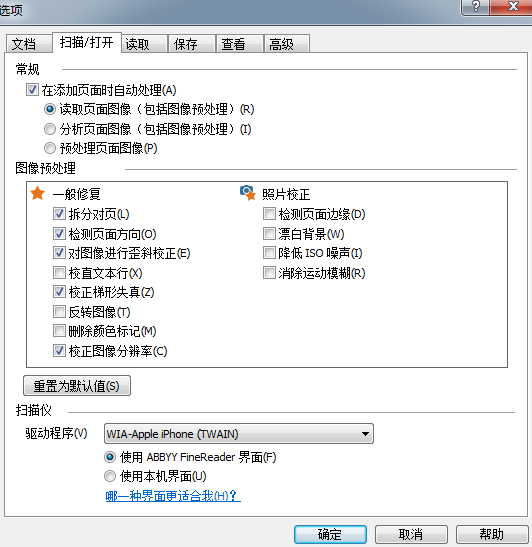
“帮助”部分详细描述了该选项以及其他选项的属性。
软件从识别的角度自动突显不同的区域类型,在这个阶段,既可以自己标出所有区域,也可以在必要时编辑分析模块检测到的区域。
FineReader的用户界面提供了多种识别区域类型,它们通过工具栏(区域被激活时位于“图像”窗口左侧)和上下文菜单显示不同选项(右击弹出):
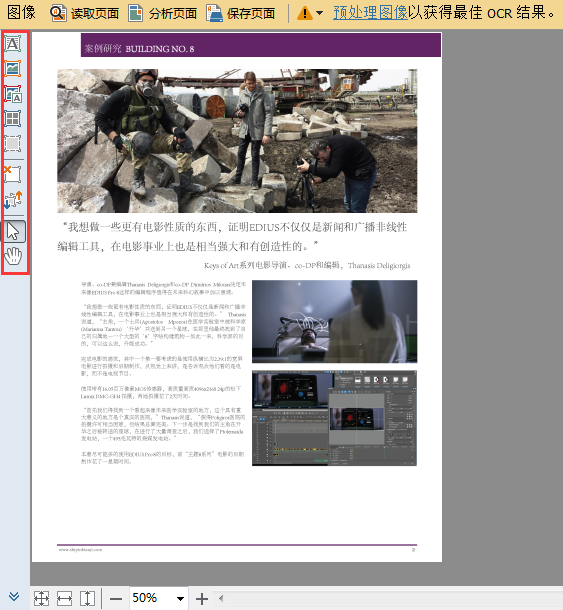
识别区域(默认为灰色框)—这是用户界面中使用的名称,这个区域是为了显示文档页面中有哪些部分需要进行识别,因此,在随后对每个“识别区域”进行分析或分析-识别以后,可能找不到或找到更多其它类型的区域,这些区域在块模板中非常有用。
文本区域 包含一行或多行文字,每行文字都具有逻辑连贯性,因此不能将两列合并到同一区块。区域形状可能不是矩形,有时需要创建或更改文本方向,或者反转颜色(通常是白底黑字,反转后就是黑底白字,但它通常会自动反转,不需要校正)。这些参数通常是针对单个区块设置的,因此同一个区块中尽量不要包含文字方向不同或颜色反转的文字段落。
关于页面上的文本方向:按照欧洲语言标准,文本方向是从上到下(如果文本被旋转,则按照逻辑从开始到结束)。但象形文字语言体系更有意思:即便是在同一页面上,某些区域也既可以包括水平文本,也可以包括垂直文本,而且这些区域中所有字符都具有相同的方向。
未完,请点击使用ABBYY FineReader识别文件的窍门(二)继续了解。
关于ABBYY FineReader的更多内容,请点击进入ABBYY中文教程,检索对您有用的信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:
PDF转成图片的方法 PDF转图片不清晰怎么办
PDF文档和图片都是常用的文件格式,在工作中我们需要根据不同的需求来灵活地对文件的格式进行更改,这就需要我们掌握PDF转成图片的方法。PDF转图片不清晰怎么办?下文中会为大家进行详细地解答。...
阅读全文 >
图片识别成文字的软件哪个好 图片识别成文字怎么操作
对于一些经常需要处理文档的小伙伴们来说,将图片中的文字转换成可编辑的文档是一大难题,甚至有些小伙伴会手动进行录入,这样不仅效率低下,也不能保证录入的正确率。实际上,将图片中的文字转换成word文档仅仅需要一些带有OCR文字识别的扫描识别软件,今天我们就来说一说图片识别成文字的软件哪个好以及图片识别成文字怎么操作。...
阅读全文 >

几款常用的OCR文字识别软件
图片文字提取软件是什么呢?随着大家的办公需求的加大,现在已经有很多的办公软件出现了,那么,图片文字提取软件便是其中的一种,因为现在制作图片的要求也比较高,所以,在图片上加入文字也是很正常的事情,那么,怎么样才能够直接将图片中的文字提取出来呢?...
阅读全文 >

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 