发布时间:2016-03-11 11: 29: 57
随着OCR文字识别概念的深入人心,人们越来越依赖有效的工具,推动日常工作的进行,想要效率比别人高,选择合适有用的软件至关重要,你看列夫•托尔斯泰的90卷著作,如果没有ABBYY FineReader OCR图文识别技术的帮助,也不可能在短短2周时间里完成数字化处理,继而上传到网络供公众阅读。
对于这样一款高效工具,小编为大家介绍过不少使用技巧和应用,但实际操作过程中难免会遇到一些问题,特别在识别文件方面,接下来我们就一起总结下使用过程中可能会出现哪些问题,以及如何处理这些问题(更多详见使用ABBYY FineReader识别文件的窍门(一))。
表格区域 包含表格,表格有可见和隐形的(或部分)分隔线:
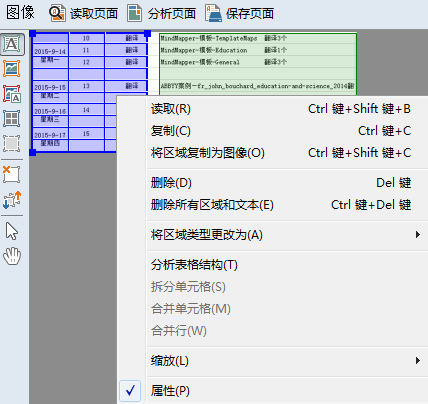
表格中可能只包含矩形,其中每个单元格也是矩形,但通过合并单元格,可以处理复杂的文本和表格结构。每个单元格可能包含要识别的文字(包括空白),也可能包含图片。如果想识别单元格中的文本,可以赋予它特殊的识别参数,否则,可以选择“图片单元格”选项。也可以选择一系列矩形单元格,将所需方案同时运用到所有的单元格。
进行自动分析时,表格是很复杂的对象,如果有些单元格分割线被隐藏,此时尤为复杂。非常重要的是,如果在识别之前修正表格布局,这比在FineReader或最终应用中修正识别结果要简单得多。
图片区域 可能不呈现为矩形。有两种类型:普通图片(占据文字的位置)和背景图片(不占据文字位置)。它们在布局上稍有不同(例如,当拖动背景图片时,图片下方的文字不会被删除)。
注意:
•只有检测到的文本单元格中的文本区域才能被识别出来。如果文本片段未被标记为识别块,就不会被识别出来。
•与图片一样,如果图像的某部分位于区域之外,或某个图像被分成几个区域,处理过程中就可能出现问题。
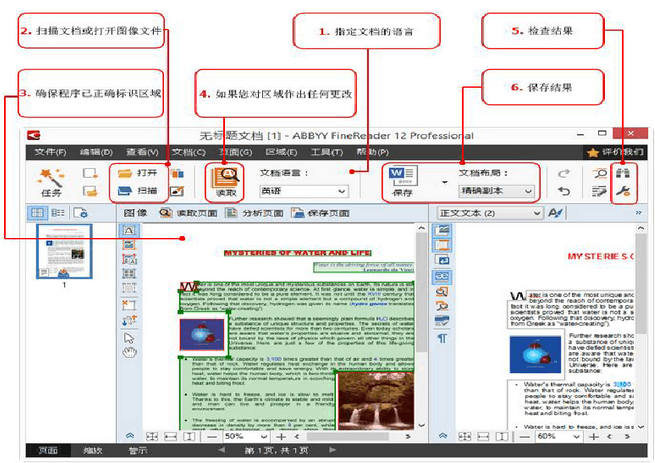
•识别语言不能掉以轻心,它们涉及众多机制,首先是分析机制:例如,亚洲语言(中日韩文)和阿拉伯语文字有其自身的特点,这些特征默认处于关闭状态,但一旦选择相应的语言,它们就会开启。
要在软件界面中正确地处理区域并理解识别和保存过程对它们的影响,以下规则非常重要:
1、如果文本和表格区域交叉,并且某些符号或部分位于多个区块—实际上这肯定是出错了—此时需要修正识别结果。图像区域也是如此,虽然它对于文本处理来说不那么重要,这些错误都应该予以修正(通常需要点几次鼠标即可)。
2、用户常常需要为大的文本区域添加背景图片,主要用途是当文本行中出现片段(象形符号、图标或公式等)时,采用所谓的行内图片,在FineReader文本模板中,它们无法正确识别或者根本无法识别。
3、在图片背景上添加文本区域也是个重要的办法:通常的作法是在图片背景上添加说明,甚至添加主文本段落。
在编辑识别文本框的时候,上述规则会体现出来。例如,如果你绘制新的识别文本框,或拉伸现有的识别文本框,使之覆盖其他区域,后者将被自动删除。
此时,要考虑你的目标是什么,以及处理后你想要得到什么格式的文件。在某些复杂情况下,以下几点可能影响到识别文本框布局的修订数量和类型:
1、只需要文字
如果需要将文件保存为双层PDF文件(页面图片以及可供搜索和复制的不可见文字层),则需要合理地选择区域:
•不应存在“垃圾”区域,这些区域中部分图片元素会被识别为文本或表格区域;
•这些区域应包含具有逻辑性的文本行,没有哪个符号同时处于几个区域,同一文本行也不会分割成两个文本区域;
•在原始文档中显示为表格的每个区域,都应选择为一个表格区域,这将有助于提高识别质量(例如,各行将被对齐),也更易于搜索与复制文本片段。
如果原始文件中的一些图片不应保留,可以不选择这些区域:不要创建新的区域,要删除自动工具选中的这些区域,至少要删除检测错误的那些图片。
2、所有信息都需要
如果文件不只包含一两列文本区域,而且最终将保存为电子图书格式(FB2、ePub或WORD、HTML等任何编辑格式),合理地选择表格和图片是极为重要的。还需要决定如何处理彼此相邻的照片组,以及如何处理图片下方或上方的说明文字。
关于ABBYY FineReader 12的更多内容,请点击进入ABBYY中文教程,检索对您有用的信息。
展开阅读全文
︾
 400-8765-888
400-8765-888 kefu@makeding.com
kefu@makeding.com读者也喜欢这些内容:

OCR图片文字识别是什么意思 OCR图片文字识别软件排行榜
随着科技的发展,OCR图片文字识别被广泛运用于办公中,但也有一些小伙伴对OCR图片识别不了解。今天小编就为大家介绍一下OCR图片文字识别是什么意思,OCR图片文字识别软件排行榜,感兴趣的话请继续看下去吧。...
阅读全文 >
pdf扫描的文件是歪的怎么办 pdf扫描件歪了如何调整
经常和文件扫描打交道的人都知道,如果文件没有摆正,扫描出来的pdf容易变歪。如果pdf扫描的文件是歪的怎么办呢?pdf扫描件歪了如何调整呢?以下会为大家提供解决方法。...
阅读全文 >

PDF转换为什么乱码 PDF转换后是乱码怎么办
很多时候,我们将PDF转换后,发现文档中竟出现了大量乱码,使得原本简单的工作变得复杂。那么PDF转换为什么乱码,PDF转换后是乱码怎么办?今天小编就给大家介绍一下如何处理这些问题。...
阅读全文 >
ABBYY FineReader 12激活教程
安装完 ABBYY FineReader 12 之后,需要激活程序才能在完整模式下运行。在受限模式下,将根据您的版本和所在地区禁用一些功能。...
阅读全文 >


 ABBYY FineReader PDF for Win
ABBYY FineReader PDF for Win 